오답노트
오답노트
Gradient Vanishing of Activation Function
보통 자주 쓰이는 Activation Function 종류: ReLU, Sigmoid, tanh, Leaky ReLU
Activation w. vanishing ? exploding?
| Activateion | Max. graident | vanishing | exploding |
|---|---|---|---|
| sigmoid | 0.25 | 매우 심함 | 없음 |
| tanh | 1 | 있음 | 없음 |
| ReLU | 1 | 음수쪽만 | 없음 |
| Leaky ReLU | 1 | 거의 없음 | 없음 |
ReLU
기본 형태
\[\text{ReLU}(x) = \max(0, x)\]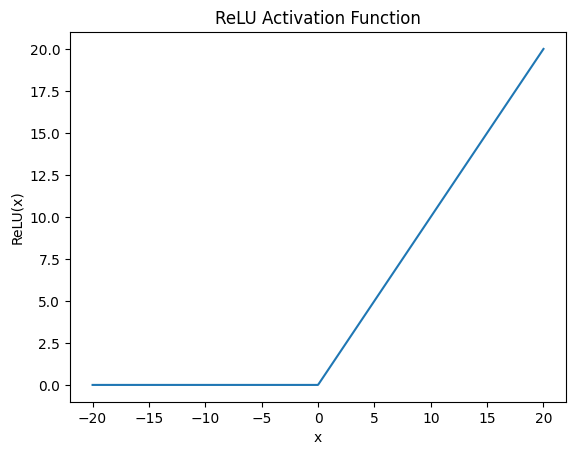
Derivative of ReLU
\[\frac{d}{dx} \text{ReLU}(x) = \begin{cases} 0, & x < 0 \\ 1, & x > 0 \end{cases}\]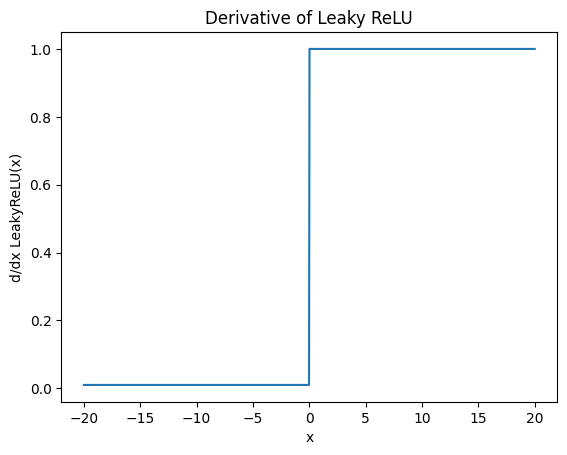
특징
- gradient = 0 OR 1
- \(x < 0\) 에서 gradient = 0 $\Rightarrow$ dying ReLU 문제
Sigmoid
기본 형태
\[\sigma(x) = \frac{1}{1 + e^{-x}}\]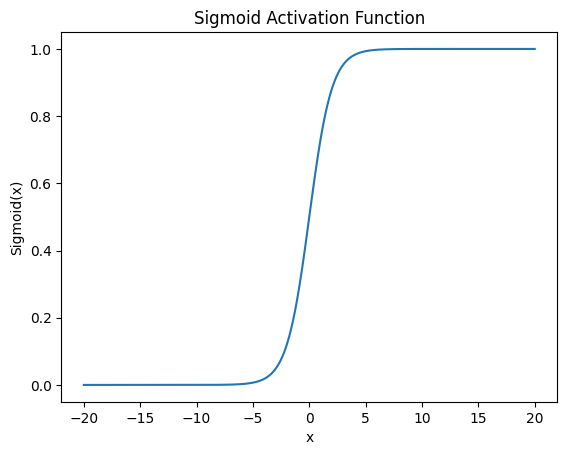
Derivative of Sigmoid
\[\sigma'(x) = \sigma(x)(1 - \sigma(x)), \quad 0 < \sigma'(x) \leq 0.25\]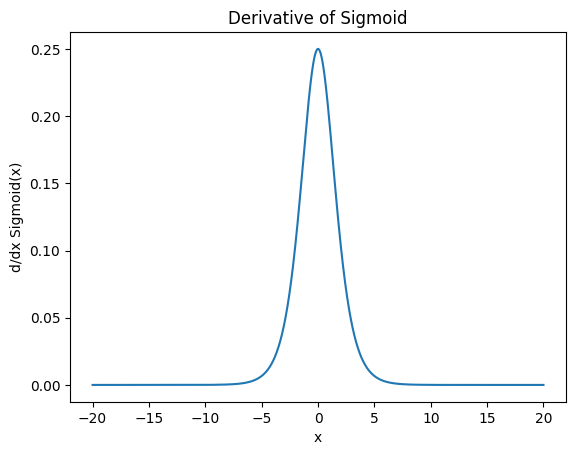
특징
- 최대 gradient 0.25
$ x $ 커지면 gradient $\to$ 0 - vanishing gradient 매우 심함
그래서 deep network 에서 거의 안씀
tanh
기본 형태
\[\tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}\]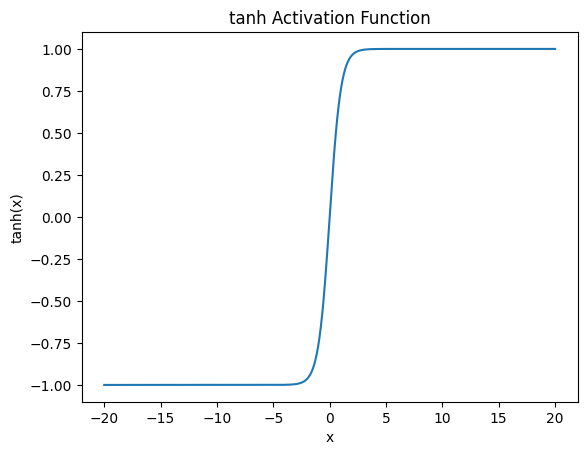
Derivative of tanh
\[\tanh'(x) = 1 - \tanh^2(x), \quad 0 < \tanh'(x) \leq 1\]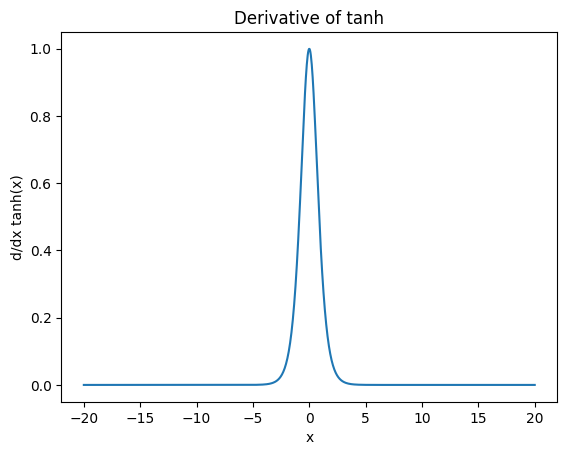
특징
- sigmoid 보다 gradient 가 크다
그래도 $ x $ 크면 vanishing gradient 발생
Leaky ReLU
기본 형태
\[\text{LeakyReLU}(x) = \begin{cases} x, & x > 0 \\ \alpha x, & x < 0 \end{cases}\]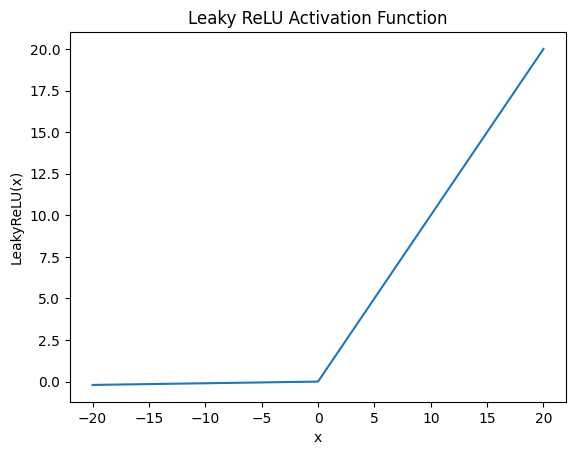
Derivative of Leaky ReLU
\[\frac{d}{dx}\text{LeakyReLU}(x) = \begin{cases} 1, & x > 0 \\ \alpha, & x < 0 \end{cases}\]
특징
- 음수 영역에서 gradient 존재.
- dying ReLU 문제를 완화시킴 .
결론적인 얘기
딥러닝에서 activation 을 고를때 다음 3가지를 핵심으로
- saturation 여부
- gradient vanishing 여부
- 계산 효율 (computational cost optimization)
그래서 실제 모델에서는 통상적으로
- hidden layer → ReLU / Leaky ReLU / GELU
- output layer → sigmoid / softmax 를 사용함.
그럼 Gradient exploding 현상은 언제 발견 되는지?
답: activation 함수 자체보다는 여러 층에서 gradient가 계속 곱해지면서 (chain rule) 커지는 구조에서 발생함.
대표적인 경우 3가지.
1. RNN
RNN에서는 같은 weight가 시간축으로 반복적으로 곱해짐.
RNN 식
\[h_t = \tanh(W_h h_{t-1} + W_x x_t)\]Backpropagation에서의 gradient:
\[\frac{\partial L}{\partial h_t} = \prod_{k=1}^{T} W_h^T \cdot \text{diag}(\tanh'(z_k))\]즉 같은 행렬이 여러 번 제곱되면서
$|W_h| > 1$일 때, $W_h^T W_h^T W_h^T \cdots$처럼 곱해지면서 gradient가 10, 100, 1000, …처럼 커짐. 그래서 RNN은 vanishing gradient, exploding gradient 둘 다 심하게 발생한다.
2. Neural Network 가 겁나 깊을 때
Layer 가 매우 많으면
\[dL /dx = W1 W2 W3 ... WL\]gradient 가 > 1 이면, 여러번 곱해지면서 점점 커짐
그래서 deep network 에서는
- Xavier initialization
- Kaiming initialization
등이 필요하다.
3. 잘못된 weight initialization
예를들어
\[W ~ Uniform(-10, 10)\]처럼 큰 weight 로 시작하면, forward pass 에서 $ z = Wx $ 가 커지고, backprop 에서는 $ W^T W^T W^T $ 가 같이 커지면서 exploding graidnet 가 발생할 수 있다.
exploding graidnet 를 어떻게 해결할 것인가?
1, Graident clipping 사용
\[g = g , ||g|| < threshold \fract{threshold}{||g||} g, otherwise\]의미 = graident 크기를 제안해보자
2. Proper Initalization
- Xavier init
- Kaiming initizlaitzion
3. Batch Normalization
gradient 스케일을 안정화 시키자
4. Residual Network (ResNet)
skip connection 으로 graident 의 흐름ㅇ르 개선하자 –>
This post is licensed under CC BY 4.0 by PythonToGo .