Deep Learning II
Summary of Deep Learning
Deep Learning II
딥러닝 모델은 어떤 데이터를 다루는가?에서 시작한다. 데이터의 구조적 특성을 활용하면 inductive bias를 제공해서 딥러닝 효율을 높일 수 있따.
Structured Data & Inductive Bias
이전챕터에서 다룬 것은 fully-connected feed-forward layers이다. 하지만 이 밖에도 다른 specific tasks/data들은 어떤 것이 있을까?
- Convolution layer (typically for images)
- Recurrent layer (typically for sequences)
- Graph convolutional layers (typically for graphs)
- etc ..
Problem Statement
우리는 100x100 픽셀이미지가 있다고 가정하자. Neural Network를 1000 unit single hidden layer로 프로세스하고자 한다. 이렇게 되면, 우리는 NN을 위해 10 million 개의 파라미터가 필요하다. 비효율의 극치. 그럼 어떻게 해결 하면 좋을까? 바로 convolution operation (합성)을 이용한다. 그리고 이것이 그 유명한 바로 CNN 이다.
Convolutional Neural Networks (CNN)
이미지처럼 픽셀 간의 local correlation이 높은 데이터에 사용된다. 수백만개의 파라미터가 필요한 fully-connected layer와 달리, 커널을 공유해 파라미터 수를 획기적으로 줄일 수 있다.
Convolution Operation
discrete 정의에서는 아래처럼 원래 알고 있는 합성곱의 정의이지만 이것은 실제 라이브러리에서 cross-correlation을 주로 구현한다. \((x * k)(t) = \sum^{\inf}_{\tau = -\inf} x(\tau)k(t - \tau)\)
Cross-Correlation
\(\hat{x}(i,j) = \sum^{L}_{l=1} \sum^M_{m=1} x(i+l, j+m)k(l,m)\)
Output size
출력크기는 Padding과 Stride에 의해 결정된다. Padding이란, 경계 처리를 위한 기법이다. 대표적인 종류는 다음과 같다.
Padding | Padding | Description | Number | | —- | — | — | | VALID | padding이 없음, output size는 감소 | $D_{l+1} = (D_l - K) + 1$, where $D_l$ =input size, $K$ Kernel width | | SAMAE (half padding) | input size와 output size를 동일하게 유지하는 전략. | add $P = \lfloor \frac{K}{2} \rfloor$ | | FULL | output size 증가 | add $(K - 1)$
Stride 커널이 이동하는 간격. \(D_{l+1} = \lfloor \frac{D_l + 2P - K}{S} \rfloor + 1\)
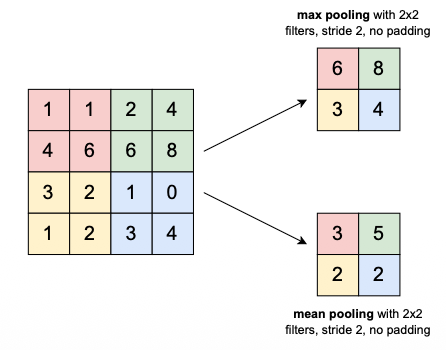
Pooling 요약 통계량을 계산해서, 작은 변화에 대한 invariance를 준다. (Max poolling, Mean pooling 등)
기타 구조
- Recurrent Neural Networks (RNN): 텍스트, 시계열 등 sequential data 처리.
- Graph Neural Networks (GNN): 소셜 네트워크, 분자 구조 등 graph data 처리.
- Attention-based models: 다양한 타입의 데이터에서 중요한 부분에 집중.
Training Deep Neural Networks
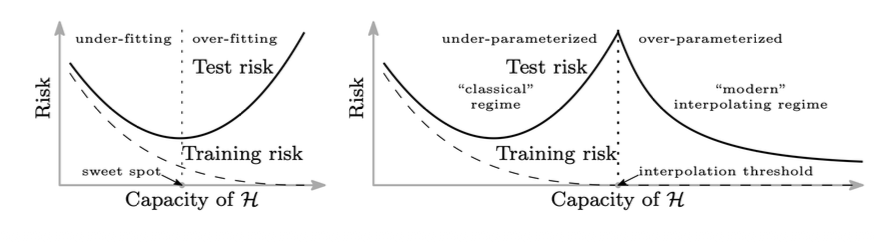
Double Descent
모델의 capacity가 일정 threshold를 넘어서면 test risk가 다시 감소하는 현상으로, over-parameterized된 NN layer가 낮은 오차를 보이는 이유로, Bias-variance tradeoff와, Empirical observation이 있다.
모델 구조를 정했다면, 실제 학습을 위해 weights를 어떻게 초기화하고 미분값을 관리할지가 관건이 된다.
Weight Initialization
Weight를 세팅할때 두가지 중요 요소가 있다.
1. Weight symmetry : Weight가 같으면, 동일한 gradient를 받아 서로 다른 특징을 배울 수 없다. 작은 랜덤값으로 symmetry breaking이 필요하다.
If two hidden units have exactly the same bias and exactly the same incoming and outgoing weights, they will always get exactly the same gradient.
Problem - They can never learn to extract different features
Solution - We break symmetry by initializing the weights to have small random values.
2. Weight scale : Weight가 너무크면, saturation을 유발하고, 너무 작으면 vanishing gradient가 발생한다.
If a hidden unit has a large fan-in, small changes on many of its incoming weights can make the unit saturate (e.g., sigmoid activation function)
If a hidden unit has a large fan-out, the gradient can be large and:
1) cause large changes to the weights during the optimization step
2) cause large changes to the weights of the previous layer in the backward pass
Problem - Wrong weight scales (mean, variance) can therefore lead to vanishing/exploding gradients
여기서 착안한 솔루션은 Xavier (Glorot) Initialization이 있다. 신호의 Variance를 유지해서 vanishing/exploding gradients 를 방지하는 방법으로, weight matrix에 zero mean and variance 를 사용한다. 다음 식을 만족하도록 설정한다. \(Var(W) = \frac{2}{\text{fan-in} + \text{fan-out}}\)
예를들어: \(W \sim \text{Uniform}(- \sqrt{\frac{6}{\text{fan-in} + \text{fan-out}}}, \sqrt{\frac{6}{\text{fan-in} + \text{fan-out}}})\)
Cf. Vanishing/Exploding Gradients
deep neural network에서는 $W^t$ 연산 중 고유값($D_{ii}$)이 1보다 크거나 작음에 따라 gradient가 폭주하거나 사라져 수렴이 불안정해지는 경우가 있다
e.g. Input에 diagonalizable Matrix $W$를 $t$번 연속해서 곱하는 상황을 가정해보자.
Eigenvalue decomposition을 하면 다음처럼 표현 가능하다. \(W = V \text{diag}(D)V^{-1}\) 여기서 $V$ Eigenvector matrix, $D$ Eigenvalues가 나열된 diagonalmatrix. 이것을 $t$번 거듭제곱하면 다음과 같아진다. \(W^t = V(\text{diag}(D))^t V^{-1}\) 그럼, gradient는 Diagonalmatrix의 Eigenvalues $D_{ii}$의 크기에 따라 결정된다.
Exploding Gradients 여기서 만약 임의의 고유값에 대해 $\lvert D_{ii} \rvert > 1.0$ 인 경우, gradient는 폭주하고, 이것은 계산을 unstable 하게 만든다.
Vanishing Gradients 여기서 만약 임의의 고유값에 대해 $\lvert D_{ii} \rvert < 1.0$ 인 경우, gradient가 매우 작아져서 네트워크의 학습(convergence)이 매우 느려지거나 혹은 멈춘다.
- Solution: gradient, clipping, batch norm 등
Regularization
안정적인 학습이 가능해졌다면, 이제 모델이 training set에만 반응하지 않도록 관리해야한다. (Overfitting problem). 모던 딥러닝에서는 capacity가 매우 커지면, test risk가 다시 감소하는 현상이 관찰된다.
통상적으로 Overfitting을 막기위해 L2 penalty (weight decay) 등을 사용한다.혹은 L1 penalty (promote sparsity)등을 사용하기도 한다. 여기에는 여러가지 방법이 있다.
| Regularization methods |
|---|
| Early stopping |
| Dataset augmentation (rotate/translate/skew/change lighting of images) |
| injecting noise |
| parameter tying and sharing |
| Dropout |
Dropout
2개의 hidden layer가 있다고 가정하자. 매번 training set이 학습되었을때, 우리는 랜덤하게 0을 히든 유닛으로 가질 확률을 %p% 라고 표기한다. 이 경우, (usually 0.5)
그럼 우리는 무작위하게 $2^H$개의 서로 다른 아키텍쳐로부터 샘플링을 할 수 있지만, 그들의 weights는 같다. 이 말을 다시 하면,
우리는 무작위하게 $2^H$개의 아키텍쳐를 공유하는 효과를 누릴 수 있다는 것이다.
Hyperparameter Optimization
layer 수, learning rate 등을 Random search나 Bayesian Optimization등 으로 최적화해서 하이퍼파라미터를 튜닝하는 방법
| Hyperparameter tuning |
|---|
| humber of hidden layers |
| number of hidden units |
| type of activation function (sigmoid, ReLU, Swish, ,,,) |
| optimizer (SGD, Adam, ADADELTA, Rpop, …) |
| learning rate schedule (warmup, decay, cyclic) |
| data preprocessing/ data augmentation |
| … |
Deep Learning Frameworks
이 모든 복잡한 연산을 효율적으로 수행하기 위애 우리는 프레임워크를 사용하고, 핵심은 computational graph의 관리방식이다.
Static (Define-and-Run)
graph를 먼저 정의하고 실행한다. JIT compilation을 통해 최적화가 가능해서 빠르다.
Dynamic (Define-by-Run)
실행 시점에 graph가 생성된다. RNN처럼 가변길이 데이터를 다룰때 유연하고 PyTorch 등이 여기 속함.
Mordern Architectures & Tricks
마지막으로 더 깊은 네트워크를 더 쉽고 빠르게 학습시키기 위한 필수 기술들이 있다.
Batch Normallization
각 layer의 활성화 값을 정규화해서 loss landscape를 부드럽게 만든다. 즉, 활성화 값의 분포를 더 안정시켜서 학습을 가속한다.
\[\hat{x} = \frac{x - E_B[x]}{\sqrt{\text{Var}_B[x]+ \epsilon}}, \text{그 이후, } y = \gamma \hat{x} + \beta \text{(학습 가능한 파라미터)} \gamma, \beta \text{도입}\]Skip Connections (Residual connections)
$y = f(x, W) + x$와 같이 이전 정보를 직접 전달해서 정보 흐름을 개선하고 매우 깊은 망도 학습가능하게 하는 방법.
캐치포인트는 미분 가능한 연산만을 사용하고, 단일 배치에 대해 overfitting되는지 먼저 확인하는 wiring check, 작은 모델부터 시작하기 등이 있음.
Linear Regression VS. Neural Network
Linear Regression 은 Weights가 적절히 설정된 Neural Network의 특수한 사례라고 볼 수 있다. 입력 $x$, Weight $W$가 모두 non-negative라면, $ReLU(xW) = xW$가 성립하므로, 이 조건에서 ReLU Neural Network의 Loss $L_{NN}$은 Linear Regression의 Loss $L_{LS}$와 동일해질 수도 있다. \(L_{NN}(W^*_{NN}) = L_{LS}(w^*_{LS})\)
그러나 일반적인 경우, Neural Network는 비선형성을 활용하므로 \(L_{NN}(W^*_{NN}) \le L_{LS}(w^*_{LS})\) 가 성립한다.