Linear Classification
Summary of linear classification, bayes' theorem, sigmoid, Hyperplane
Linear Classification
Intro 2 Classification
Classification은 입력값 \(x\)를 \(C\)개의 정해진 클래스 중 하나로 분류하는 작업이다. (vs. Regression)
\[y \in \{1,\ldots,C\}\]Zero-one loss
예측값 \(\hat{y}\)의 품질을 측정하는 가장 기본 단위로, 분류가 잘못된 샘플의 개수를 센다. 수식으로 표현하면 다음과 같다:
\[\ell_{01}(y, \hat{y}) = \sum_{i=1}^N I(\hat{y} \neq y_i)\]Decision Boundary (Hyperplane)
두 클래스를 구분하는 결정 경계, Hyperplane으로 정의되고, 파라미터 \(w\), \(w_0\)에 의해 \(w^T x + w_0 = 0\)인 지점이다.
Perceptron Algorithm
가장 오래된 이진 분류 알고리즘 중 하나로, 오분류된 샘플 \(x_i\)에 대해 \(w\)와 \(w_0\)를 반복적으로 업데이트해서 선형 분리가 가능한 경우 반드시 수렴한다.
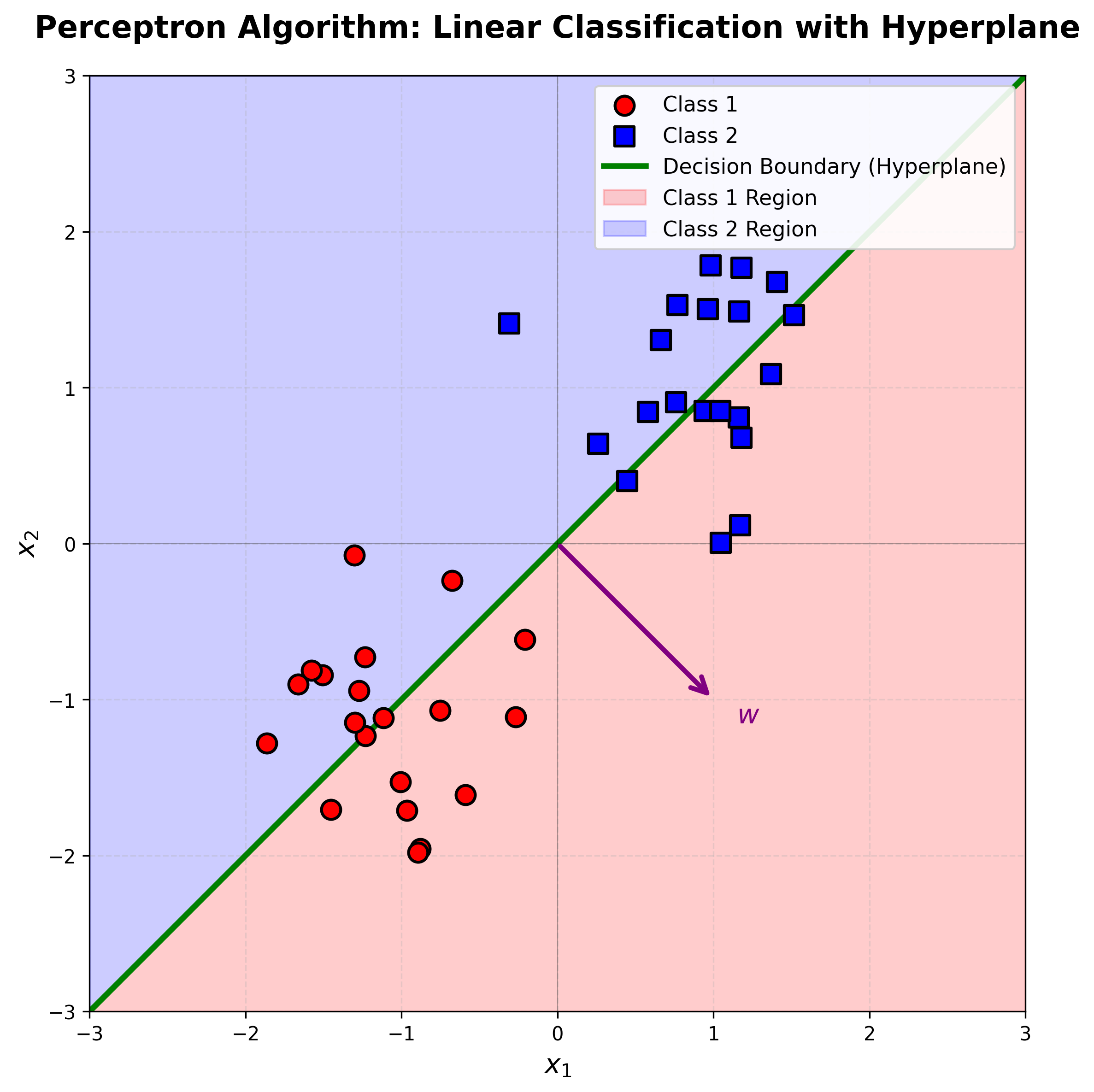
Multiclass Strategies
- One-versus-Rest: 각 클래스마다 하나의 Hyperplane을 학습시킨다
- One-versus-One: 클래스 쌍마다 Hyperplane을 학습시키고, Majority vote(다수결)로 결정한다
- Multiclass discriminant: \(C\)개의 선형 함수 \(f_c(x) = w_c^T x + w_{0_c}\) 중 가장 큰 값을 내는 클래스를 선택한다
Probabilistic Generative Models
데이터의 생성 과정을 모델링해서 Bayes’ theorem을 통해 posterior probability $p(y=c \mid x)$를 구하는 방식이다. 기본적으로 모델은 다음과 같이 수식화 가능하다:
\[p(y=c \mid x) \propto p(x \mid y=c)p(y=c)\]여기서 \(p(x \mid y=c)\)와 \(p(y=c)\)의 의미를 분석해보자.
- Class Prior \(p(y=c)\)는 Categorical distribution을 따르고, MLE 결과는 각 클래스의 비율이 \(\pi_c = \frac{N_c}{N}\)이다
- Class Conditional \(p(x \mid y=c)\)는, 연속형 데이터의 경우 Multivariate Normal \(\mathcal{N}(x \mid \mu_c, \Sigma)\)를 사용한다
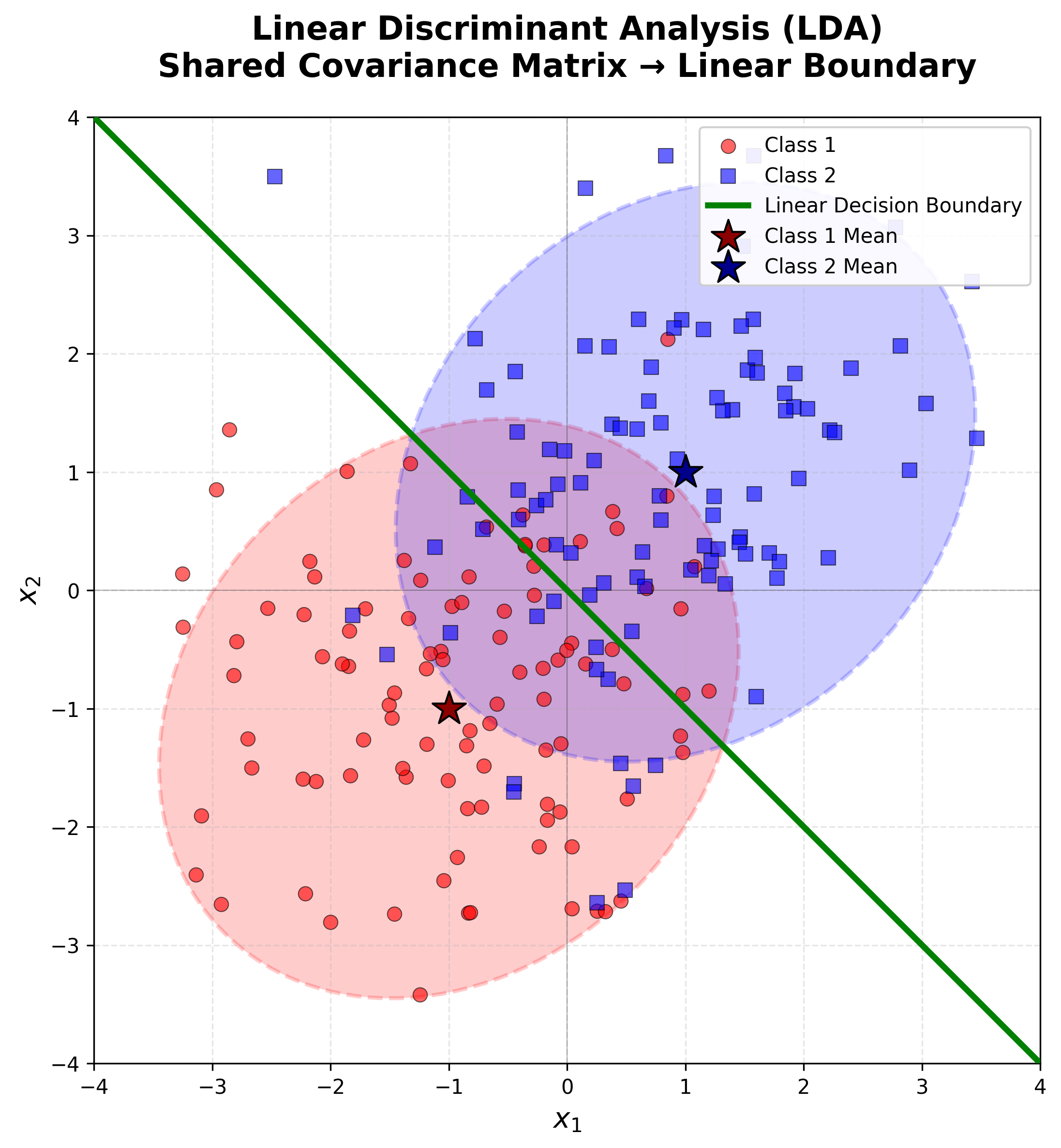
Linear Discriminant Analysis (LDA)
💡 가정: 모든 클래스가 동일한 Covariance Matrix \(\Sigma\)를 공유한다고 가정해보자.
그렇다면 MLE는 어떻게 될까?
- \(\mu_c\)는 클래스 \(c\)에 속한 샘플들의 평균이다
- \(\Sigma\)는 각 클래스 표본 공분산 \(S_c\)의 가중 평균이다
여기서 Log의 확률 비율을 계산하면 \(x\)에 대한 선형식 \(w^T x + w_0\)이 되고, 이것은 Linear decision boundary를 이룬다.
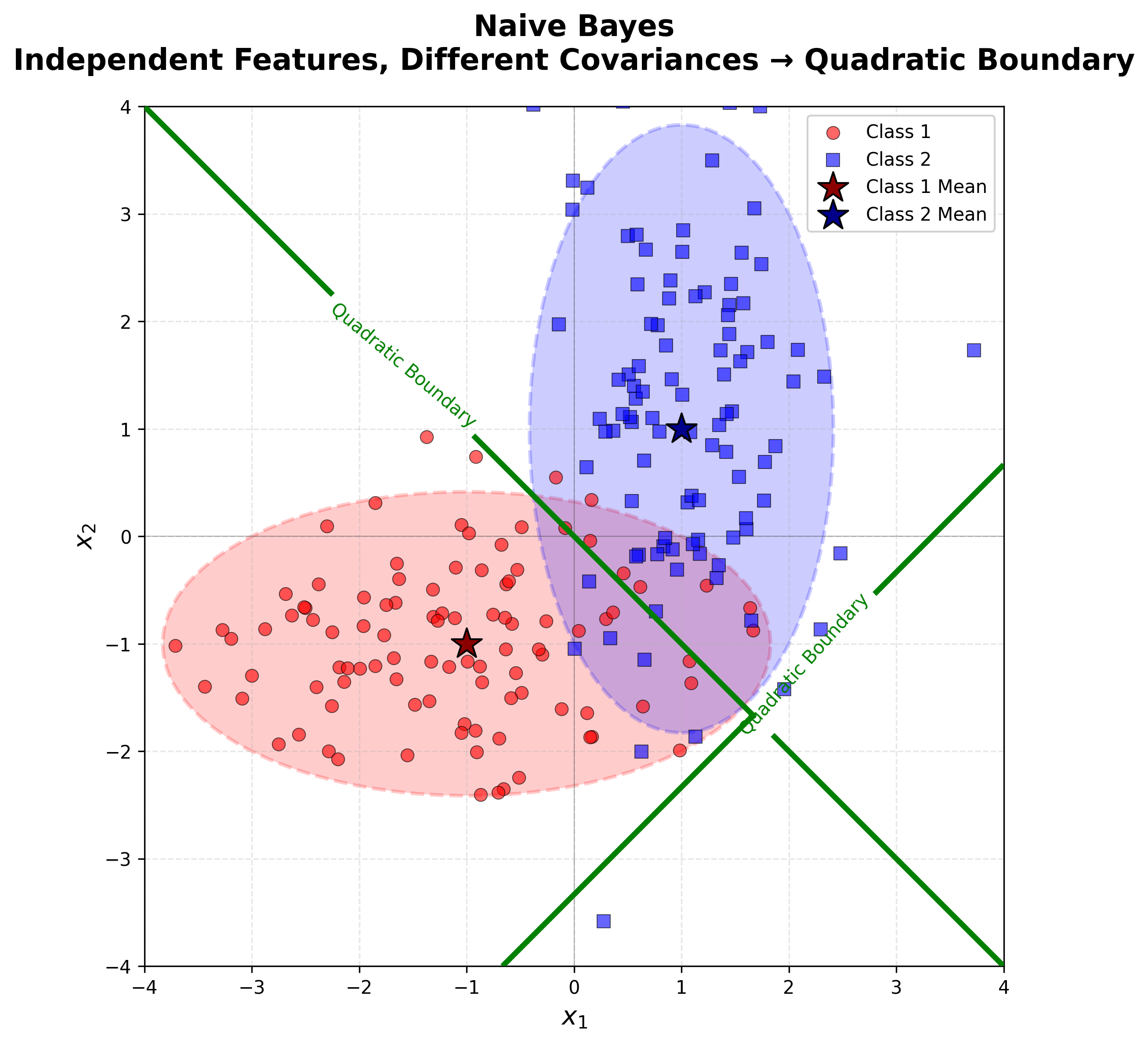
Naive Bayes
💡 가정: 클래스가 주어졌을 때 features들이 서로 independent라고 가정해보자.
이 경우 Covariance matrix는 Diagonal matrix가 되며, 클래스마다 서로 다른 \(\Sigma_c\)를 사용한다. 그리고 이 \(\Sigma_c\)가 서로 다르기 때문에, \(x\)에 대한 2차항이 살아남아 Quadratic decision boundary를 형성한다.
Probabilistic Discriminative Models
이번엔 사후 확률 \(p(y \mid x)\)를 직접 모델링하는 방법이다. 대략 3가지 정도의 방법이 있는데, Logistic Regression, Multiclass Logistic Regression, Weight Regularization 정도가 있다.
Logistic Regression
Binary classification을 \(p(y=1 \mid x) = \sigma(w^T x)\)로 모델링한다. 여기서 \(\sigma(a) = \frac{1}{1+e^{-a}}\)는 Sigmoid function이다.
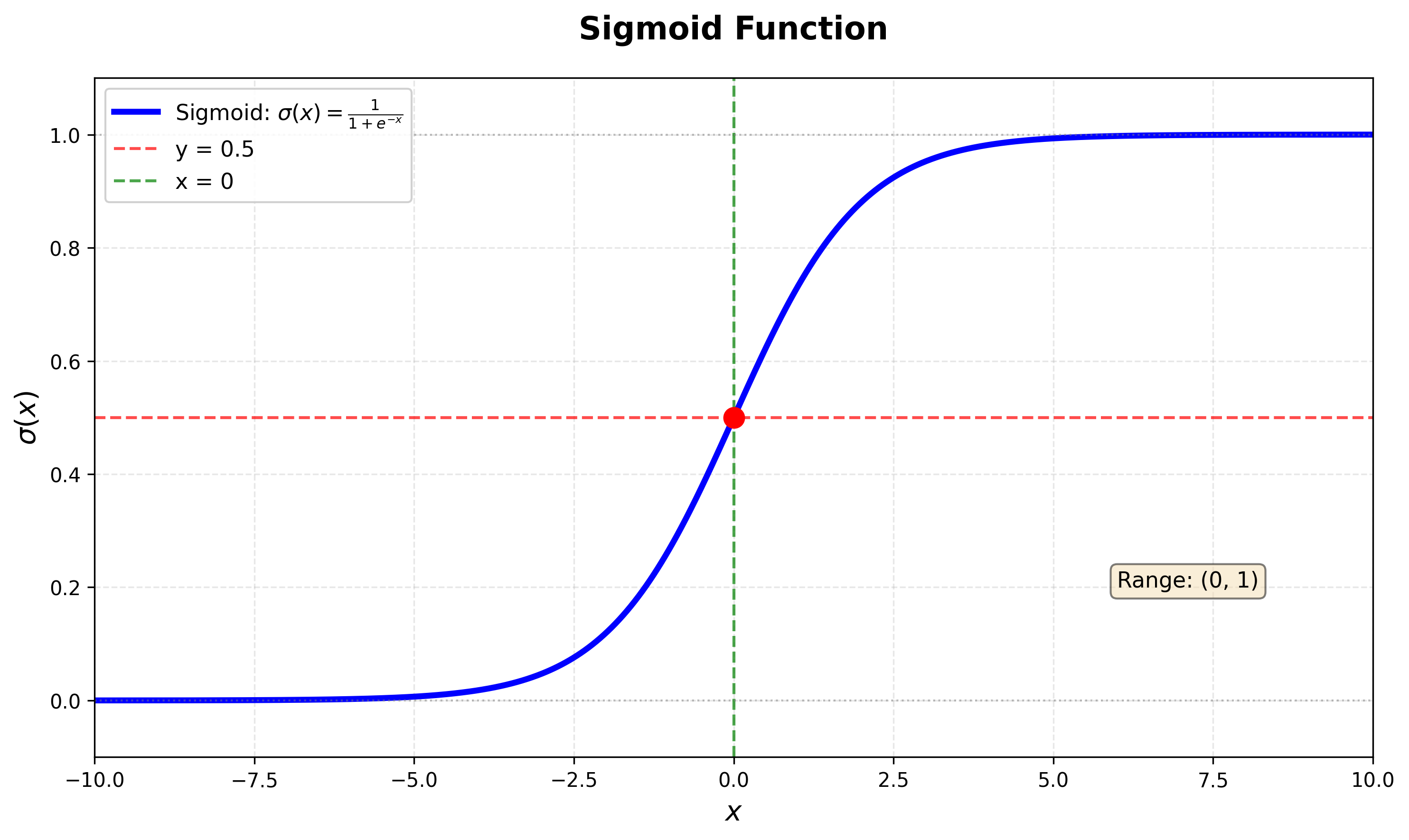
- Negative Log-Likelihood: Loss Function으로는 Binary Cross Entropy를 사용한다
- Optimization: Closed-form solution이 존재하지 않으므로, 최적화가 필요하다
Multiclass Logistic Regression
Softmax function을 사용해서 여러 클래스에 대한 확률을 출력한다:
\[p(y=c \mid x) = \frac{\exp(w_c^T x)}{\sum_{c'} \exp(w_{c'}^T x)}\]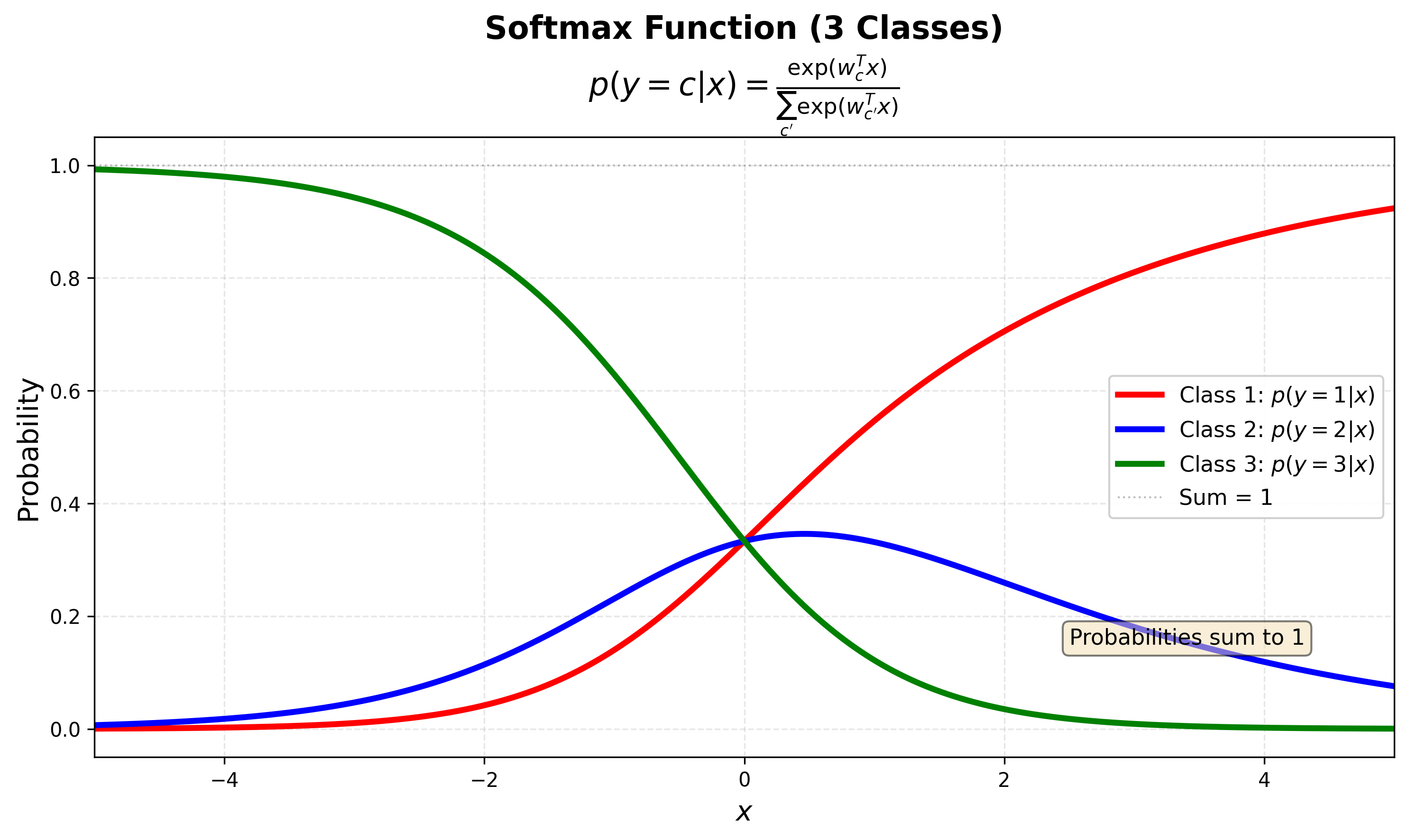
- Loss Function은 Cross Entropy를 사용하며, 타겟은 One-hot encoding으로 표현된다
Weight Regularization
Overfitting을 방지하기 위해 페널티를 추가하는 전략. 페널티의 형태는 다음과 같다:
\[E(w) + \lambda ||w||_q^q\]Key Insights
1. Limitation of MLE (Linearly Separable Data)
데이터가 선형적으로 완벽히 분리될 경우, MLE를 통한 \(w\)의 크기가 무한대로 발산하게 된다. \(\| w \| \to \infty\) 이를 해결하기 위해 Weight regularization은 필수적이다.
2. Differentiation of Sigmoid
\[\frac{d\sigma(a)}{da} = \sigma(a)(1 - \sigma(a))\]3. Identifiability
\(C\)개 클래스에 대해 \(C\)개의 파라미터 벡터를 사용하는 Softmax 모델은 중복성이 있다. 따라서 한 클래스의 가중치를 0으로 고정하는 제약을 두기도 하는데, 이진 분류에서 Sigmoid를 사용하는 것이 바로 이 제약이 포함된 형태이다.
4. Generative vs. Discriminative
일반적으로 판별 모델이 분류 성능이 더 뛰어나지만, 생성 모델은 누락된 데이터 처리나 아웃라이어 탐지에 더 유리하다.
결론
Linear Classification은 Decision Boundary를 직선 또는 Hyperplane으로 설정하는 것을 의미하고, 이를 확률적으로 접근할 때 Generative (클래스별 데이터 분포를 가정) 또는 Discriminative (경계 자체를 직접 학습)에 따라 LDA와 Logistic Regression 등으로 나눈다.