Linear Regression
Summary of linear regression, Regularization, Bias-Variance TradeOff
Linear Regression
Basic Concept
Linear Regression의 목적은 입력값 \(x\)와 타겟 \(y\) 사이의 매핑 함수 \(f(\cdot)\)를 찾는 것이다.
Model Assumption
타겟 \(y\)는 결정론적 함수 \(f(x)\)에 Noise \(\epsilon\)이 더해진 형태이고, \(\epsilon\)은 평균이 0인 정규 분포를 따른다고 가정한다. 즉 수식으로 표현하면:
\[y_i = f(x_i) + \epsilon_i, \quad \epsilon_i \sim \mathcal{N}(0, \beta^{-1})\]Linear Model
\(f(x)\)가 파라미터 \(w\)에 대해 선형인 모델이다. Bias term \(w_0\)을 \(w\) 벡터에 포함하고, 입력 \(x\) 앞에 1을 추가해서 Absorbing the bias를 수행하면, \(f_w(x) = w^T x\)로 간결하게 표현된다.
Least Squares (LS) Loss
모델의 오차를 측정하기 위해 관측값과 예측값 차이의 제곱합을 사용한다. 이것이 그 유명한 손실 함수:
\[E_{LS}(w) = \frac{1}{2} \sum_{i=1}^N (w^T x_i - y_i)^2\]Normal Equation
우리는 손실을 최소화해야 한다. 손실 함수 \(E_{LS}(w)\)에 대한 최적의 값을 \(w^{*}\)라고 하고, 이것은 그래디언트를 0으로 설정해서 구한다 (~편미분 느낌):
\[w^{*} = (X^T X)^{-1} X^T y\]여기서 \((X^T X)^{-1} X^T\)는 Moore-Penrose pseudo-inverse \(X^{\dagger}\)라고 부른다.
Nonlinear Dependency & Basis Functions
그렇다면 데이터가 비선형적이면 어떻게 될까? 일단 뭐가 됐든 선형이 비선형보다 calculation이 쉽기 때문에 우리는 어떤 함수든 최대한 선형 함수로 transform하는 전략을 선택해야 한다.
Input \(x\)를 고차원 공간으로 변환하는 Basis functions \(\phi(x)\)를 사용해서 선형 모델의 틀을 유지하면서 비선형 관계를 학습할 수 있다. (약간 커널 느낌)
Prediction
\[f_w(x) = w^T \phi(x)\]Design Matrix \(\Phi\)
모든 데이터 포인트에 대한 기저 함수의 값을 행으로 쌓은 행렬이다.
Solution
최적해는 기본 모델과 동일한 형태이다:
\[w^{*} = (\Phi^T \Phi)^{-1} \Phi^T y\](형태가 같으니 선형처럼 다루면 된다.)
Transformation Invariance
만약 입력을 선형 변환하더라도 (\(\phi(x_i) = A^T x_i\), 여기서 \(A\)는 Full rank), 최적의 파라미터 \(v^{*}\)가 \(A^{-1}w^{*}\)가 되어 결국 동일한 prediction function \(f(x) = g(x)\)를 생성한다.
여기서 문제가 나온다. 모든 함수를 다 선형 함수로 때려박으면 모델이 점점 복잡해진다. 이렇게 되면 weight인 \(w\)가 매우 커지면서 Overfitting이 발생한다. 이를 해결하기 위해 우리는 큰 weight에 페널티를 부여하는 익히 들어본 Regularization을 사용한다.
Regularization & Ridge Regression
여기서 Ridge, Lasso, L1, L2 등이 등장한다.
Ridge Regression Loss & Solution
수식을 보면 다음과 같다:
\[E_{ridge}(w) = \frac{1}{2} \sum_{i=1}^N (w^T \phi(x_i) - y_i)^2 + \frac{\lambda}{2} ||w||^2_2\]여기서 \(\lambda\)는 얼마나 페널티를 강하게 부여할 것인가의 파라미터, 즉 Regularization strength이다.
이에 대한 최적해는 다음과 같다. (이 최적해의 형식도 결국 앞선들과 비슷함):
\[w^{*} = (\Phi^T \Phi + \lambda I)^{-1} \Phi^T y\]\(\lambda I\)가 추가된 것이 특징인데, 데이터 샘플 수 \(N\)이 기저 함수의 수 \(M\)보다 적을 때 발생하는 Singularity 문제를 해결할 수 있다는 장점이 있다. Singularity 문제는, non-invertible, 즉 역행렬이 존재하지 않는 이슈를 뜻한다.
💡 참고: Ridge regression은 타겟 벡터에 0을, Design matrix에 \(\sqrt{\lambda} I\)를 추가한 일반 Least squares 문제와 수학적으로 동일하다.
Bias-Variance Tradeoff
모델의 예측 에러는 두 가지 요소로 분해된다: Bias, Variance
Bias
모델의 가정이 너무 단순해서 발생하는 에러 (=Underfitting)이다. 예를 들어 3차 다항식 데이터를 선형 회귀로 학습하면:
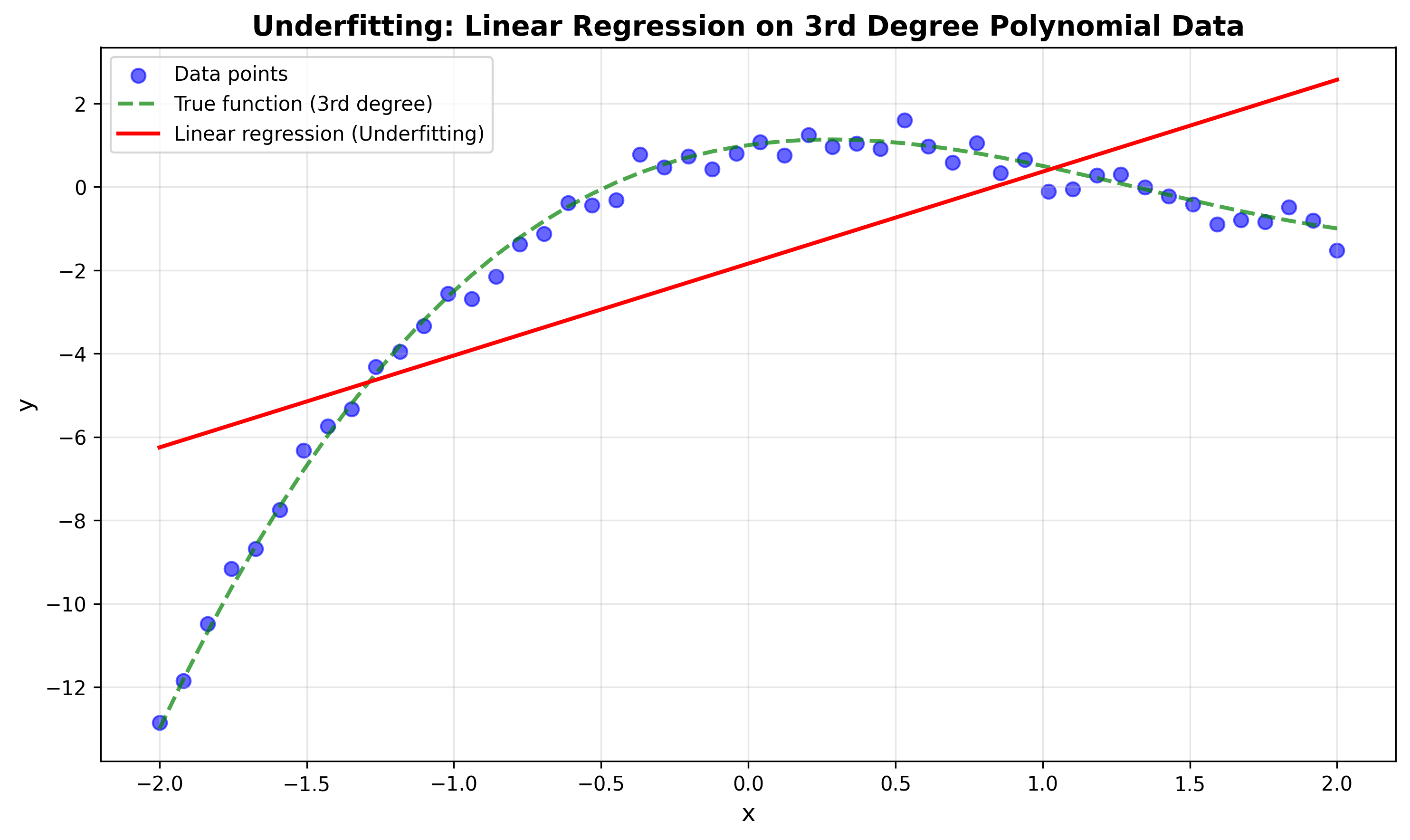
위의 이미지처럼 학습이 잘 이루어지지 않으며 이것을 Underfitting이라고 함.
Variance
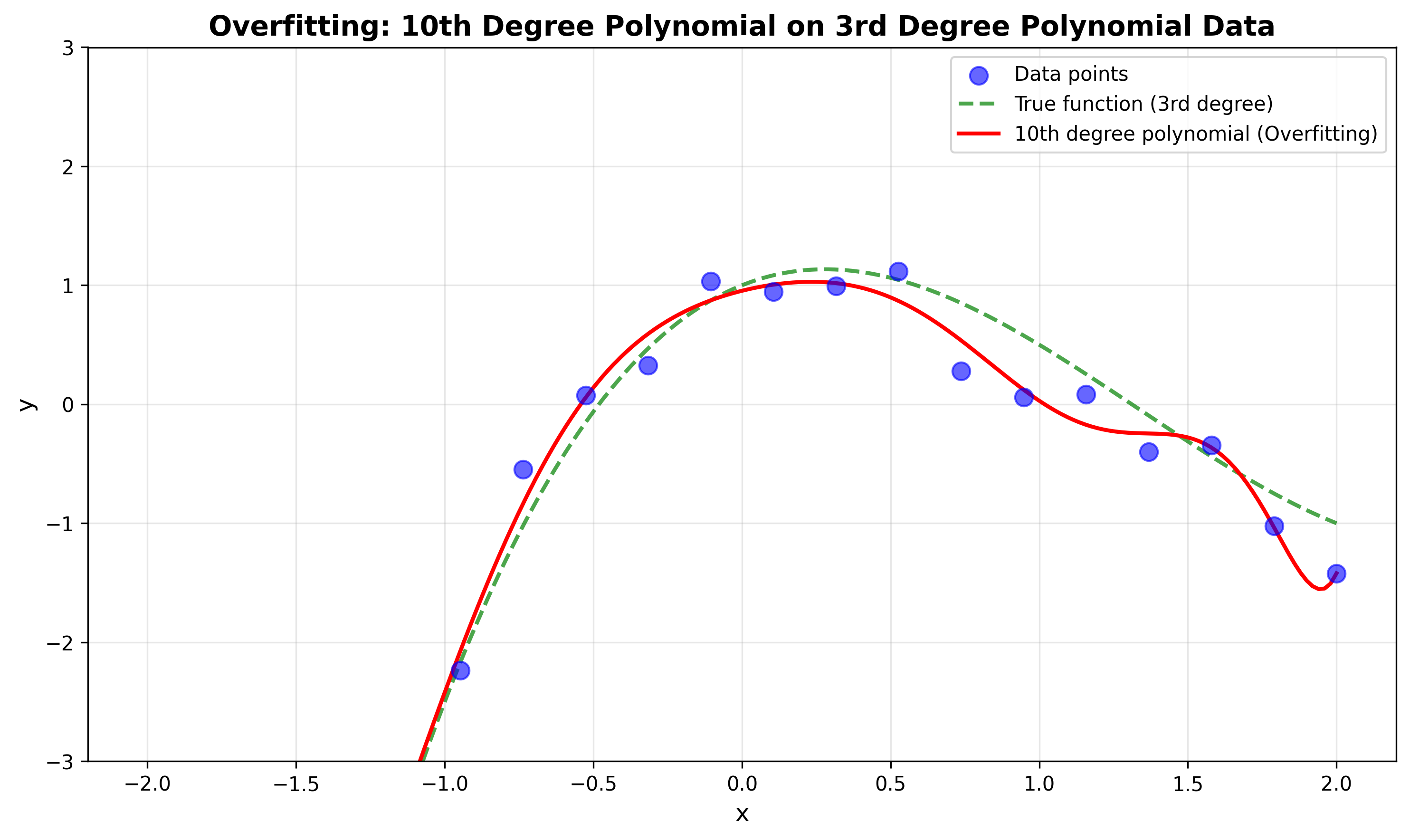
모델이 너무 유연해서 데이터의 노이즈까지 학습하며 발생하는 이슈이다. Overfitting이라고 하고, 예를 들어 3차 다항식 데이터를 10차 다항식으로 학습하면:
위의 이미지처럼 너무 잘 맞는 문제가 발생한다.
전략
그럼 여기서 우리가 취해야 할 전략은 무엇인가?
일반적으로 High capacity Model을 선택하되, Regularization을 통해 Variance를 조절하는 방식을 취한다. 그리고 모델의 복잡도 \(M\)를 선택할 때는 Training set이 아닌 Validation set에서의 에러를 기준으로 해야 한다.
Probabilistic Linear Regression
이런 Regression 문제를 이전 챕터에서 배웠던 확률 모델로 공식화해서 최적화를 사용하는 접근 방식의 의미를 다시 풀어보자.
Maximum Likelihood Estimation (MLE)
- Likelihood \(p(y \mid X, w, \beta)\)를 최대화하는 것은 Least squares error를 최소화하는 것과 수학적으로 동일하다
- Noise precision \(\beta\)의 MLE 추정치는 예측 오차의 평균의 역수와 같다
Maximum a Posteriori (MAP)
- Weight \(w\)에 Zero-mean Gaussian Prior \(p(w \mid \alpha) = \mathcal{N}(w \mid 0, \alpha^{-1} I)\)를 가정한다
- MAP Estimation은 Ridge regression을 수행하는 것과 동일하며, 이때의 Regularization strength는 \(\lambda = \frac{\alpha}{\beta}\)가 된다
Fully Bayesian Linear Regression
- Weight의 점 추정치가 아닌 Posterior distribution \(p(w \mid D) = \mathcal{N}(w \mid \mu, \Sigma)\) 전체를 구한다
- Posterior Predictive Distribution: 새로운 데이터 \(x_{new}\)에 대해 예측할 때, 파라미터 \(w\)의 불확실성을 integrate한다. 즉 수식으로 표현하면:
- 이 방식은 입력 \(x_{new}\)에 따라 달라지는 예측의 Uncertainty를 정확하게 구현할 수 있다
기타
Weighted Least Squares
각 데이터 포인트에 weight \(t_i\)가 부여된 경우, 이는 각 포인트의 Noise variance가 \(\frac{1}{t_i}\)로, 서로 다르다고 모델링하는 것과 같다.
Normal-Gamma Prior
만약 평균 \(w\)와 정밀도 \(\beta\)를 모두 모를 경우, 이 둘에 대한 Conjugate prior로 Normal-gamma distribution을 사용한다.
결론
요약하자면 Linear Regression은 단순히 선을 긋는 것이 아니라, 확률적으로는 노이즈가 섞인 데이터의 Likelihood를 최대화하는 과정이고, Regularization은 파라미터에 대한 Prior 지식을 도입해서 모델의 복잡도를 제어하는 도구이다.