Optimization
Summary of Optimization
Optimization
Introduction
Machine Learning의 많은 작업은 Objective function을 최소화하거나 최대화하는 Optimization 문제로 귀결된다. 예를 들어, Linear Regression에서 예측 오차 제곱합, Logistic Regression에서는 Negative Log-Likelihood를 최소화하는 가중치를 찾는 것이다.
이런 최적화 문제에서 우리의 목표는 global minimum/maximum을 찾는 것이다. 하지만 일반적인 함수에서는 여러 개의 local minimum이 존재할 수 있어, 어디서 시작하느냐에 따라 다른 결과에 도달할 수 있다. 이는 최적화를 어렵게 만드는 주요 원인이다.
Convexity
이러한 어려움을 해결하기 위해, 우리가 다루는 함수가 Convex한지 확인하는 것이 중요하다. Convex 함수는 최적화하기 쉬운 특별한 성질을 가지고 있기 때문이다.
Function이 Convex하다는 것은:
- Convex Set: 집합 내의 임의의 두 점을 연결한 선분이 다시 그 집합 안에 포함되는 경우
- Convex Function: 함수 위의 두 점을 이은 선분이 항상 함수 그래프보다 이상에 위치하는 함수:
여기서 \(\lambda \in [0, 1]\)이다.
- Convex 함수는 그릇 모양과 같아서 어디서 시작하든 아래로 내려가다 보면 반드시 전체에서 가장 낮은 곳에 도달한다. 즉, 모든 Local minimum이 곧 Global minimum이 된다. 이는 최적화 알고리즘이 어디서 시작하든 올바른 답을 찾을 수 있음을 보장한다.
왜 Convexity가 중요한가?
Convex 함수에서는 gradient가 0인 지점이 곧 global minimum이 된다. 이는 단순히 “내려가는 방향”을 따라가기만 해도 최적해에 도달할 수 있음을 의미한다. 반면 non-convex 함수에서는 local minimum에 갇힐 위험이 있어 더 정교한 기법이 필요하다.
Verifying Convexity
어떤 함수가 최적화하기 쉬운지 판단하기 위해 다음 기준을 사용한다.
First-order condition
미분 가능한 함수 \(f\)가 Convex일 필요충분조건은 다음과 같다:
\[f(y) \geq f(x) + (y-x)^T \nabla f(x)\]직역하면, 함수의 모든 지점에서의 접선이 항상 실제 함수 그래프보다 아래에 위치한다. 즉, 접선이 함수의 바닥 역할이고, 함수가 위로 솟아오르는 속도를 보장한다.
Second-Order condition
두 번 미분 가능한 함수에서 Hessian matrix가 Positive Semi-definite (\(\nabla^2 f(\theta) \succeq 0\))이면 convex이다. 그리고 Convexity는 함수의 합, 곱, max 연산 등에서 성질이 유지된다.
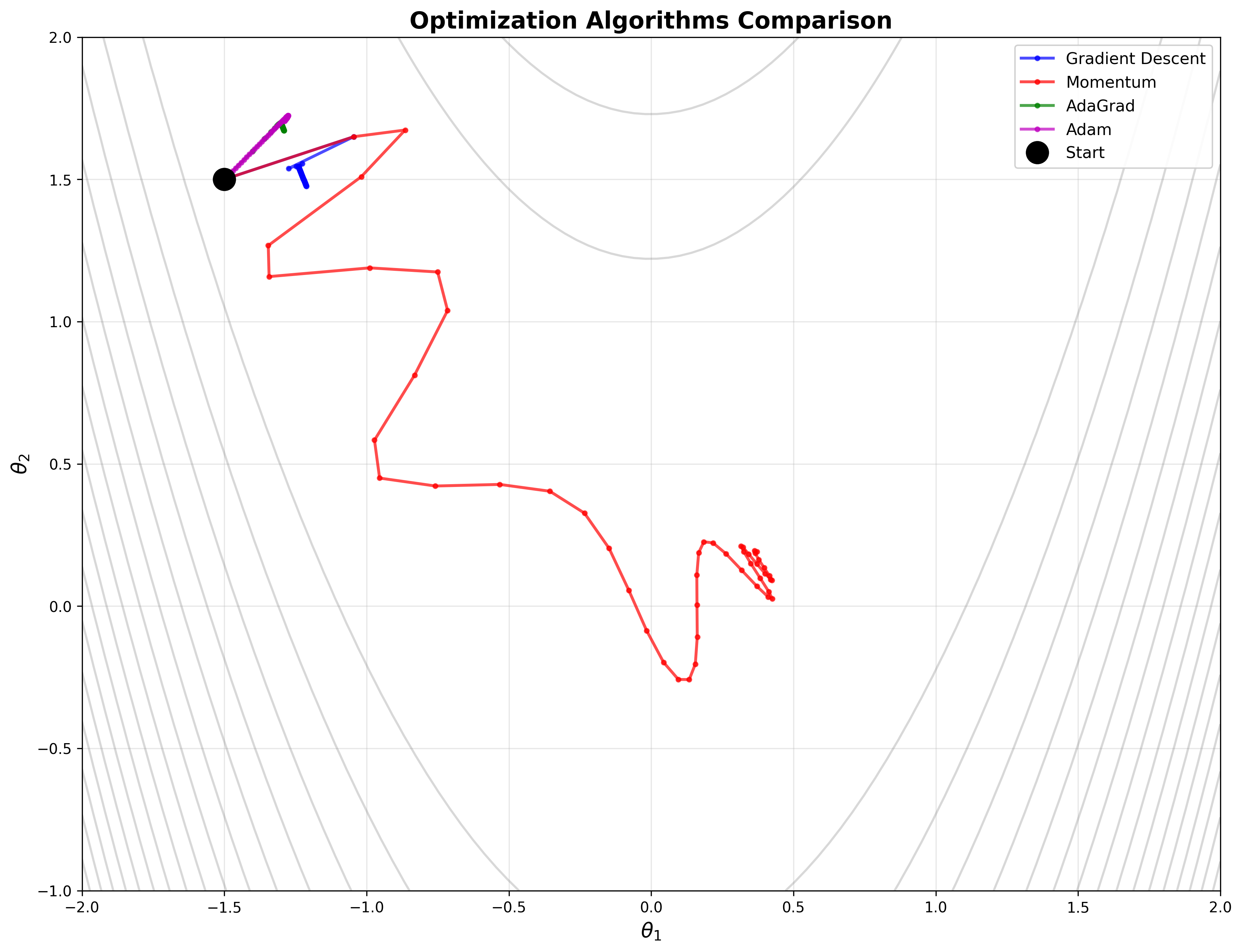
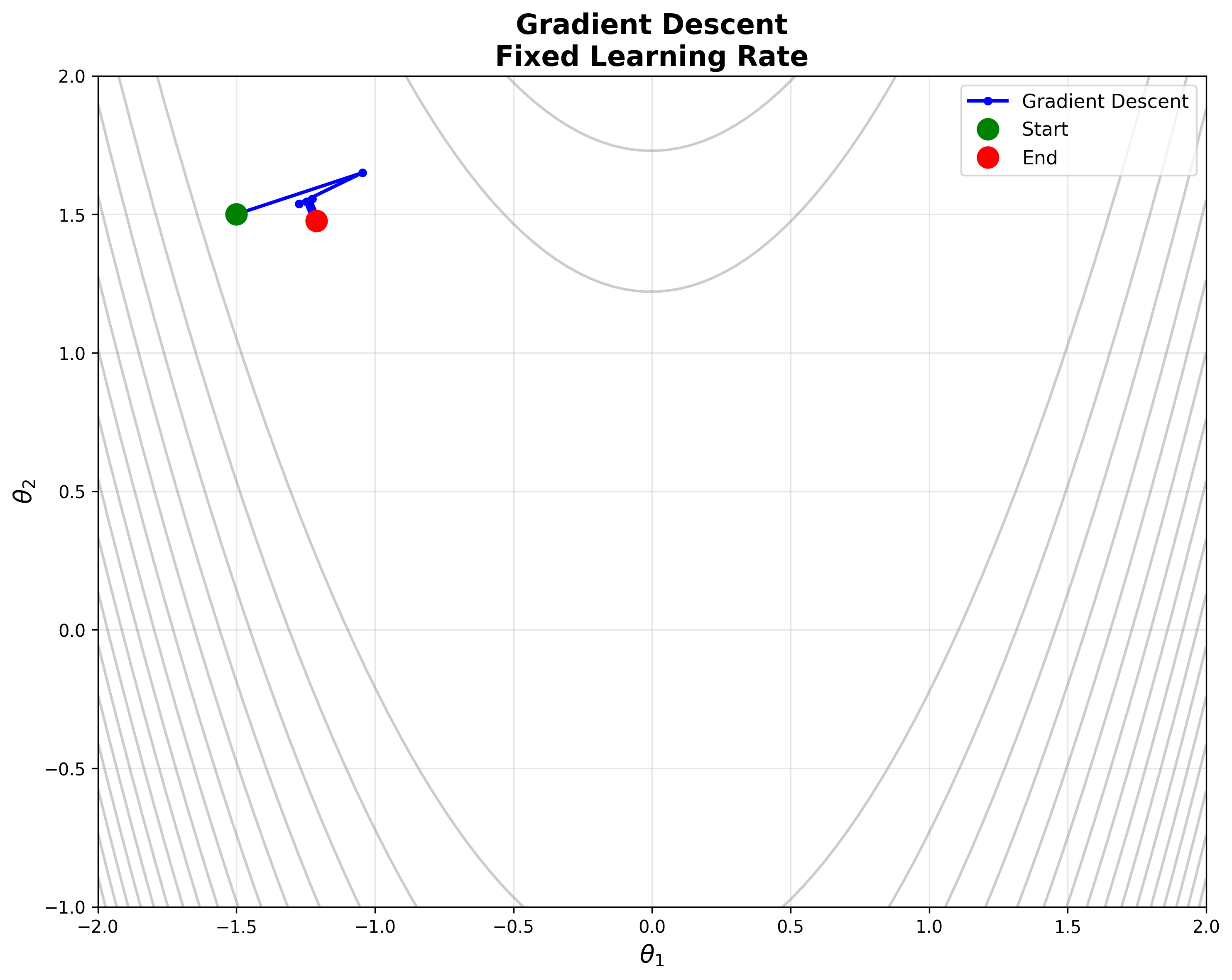
Gradient Descent
Convex 함수의 성질을 활용하는 가장 기본적인 최적화 방법이 Gradient Descent이다. 이 방법은 함수의 gradient(기울기) 정보만을 사용하여 최적해를 찾아간다.
가장 가파른 내리막 방향으로 한 걸음씩 이동하는 기법이다. 한 걸음은 매 회마다 업데이트 된다.
Update Rule
\[\theta := \theta - \tau \nabla f(\theta)\]Learning Rate (\(\tau\))
- 너무 작은 경우: 경사하강에 너무 많은 시간 소요, Local minima에 갇힐 수 있음
- 너무 큰 경우: 경사하강이 너무 급격하게 이루어지며 밑바닥을 지나쳐 반대편 벽으로 튀어오르는 Oscillation이 발생한다
Gradient Descent의 한계
고정된 학습률을 사용하는 기본 Gradient Descent는 단순하지만, 실제로는 여러 문제에 직면한다. 함수의 지형이 복잡하거나, 일부 방향으로는 가파르고 다른 방향으로는 완만한 경우, 모든 방향에 동일한 보폭을 적용하는 것은 비효율적이다. 또한 과거의 이동 정보를 전혀 활용하지 못해 진동(oscillation)이 발생하거나 수렴이 느려질 수 있다.
Adaptive Learning Rates
이러한 한계를 극복하기 위해, 과거의 Gradient 정보를 활용하여 학습률을 동적으로 조절하는 방법들이 개발되었다. 이들은 모두 같은 핵심 아이디어를 공유한다: “지금까지 어떻게 움직였는지 기억하고, 그것을 바탕으로 다음 보폭을 결정한다.”
Momentum - 관성
과거의 이동 방향(\(m_{t-1}\))을 일정 비율($\gamma$, 보통 0.9)만큼 유지한다. 그래디언트가 같은 방향을 가리키면 가속도가 붙고, 방향이 바뀌면 진동을 억제해서 더 빠르게 수렴하게 돕는다.
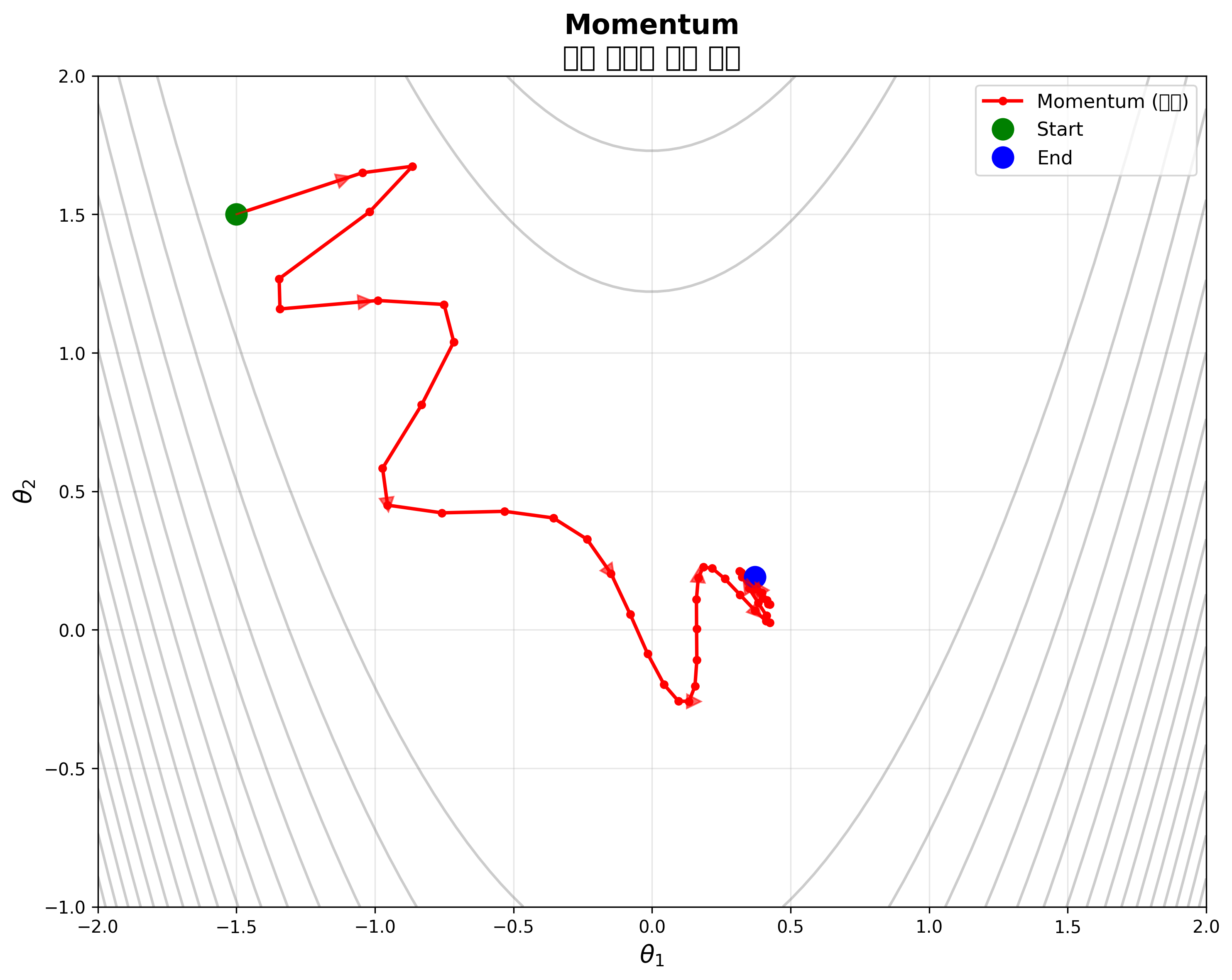
- \[m_t = \tau \cdot \nabla f(\theta_t) + \gamma \cdot m_{t-1}\]
- \[\theta_{t+1} = \theta_t - m_t\]
1st Moment는 과거 그래디언트의 지수 이동 평균으로, 관성 효과를 제공한다.
AdaGrad
파라미터마다 서로 다른 Learning rate를 적용한다. 업데이트가 많이 된(그래디언트가 컸던) 파라미터는 보폭을 줄이고, 업데이트가 적었던 파라미터는 보폭을 크게 유지한다.
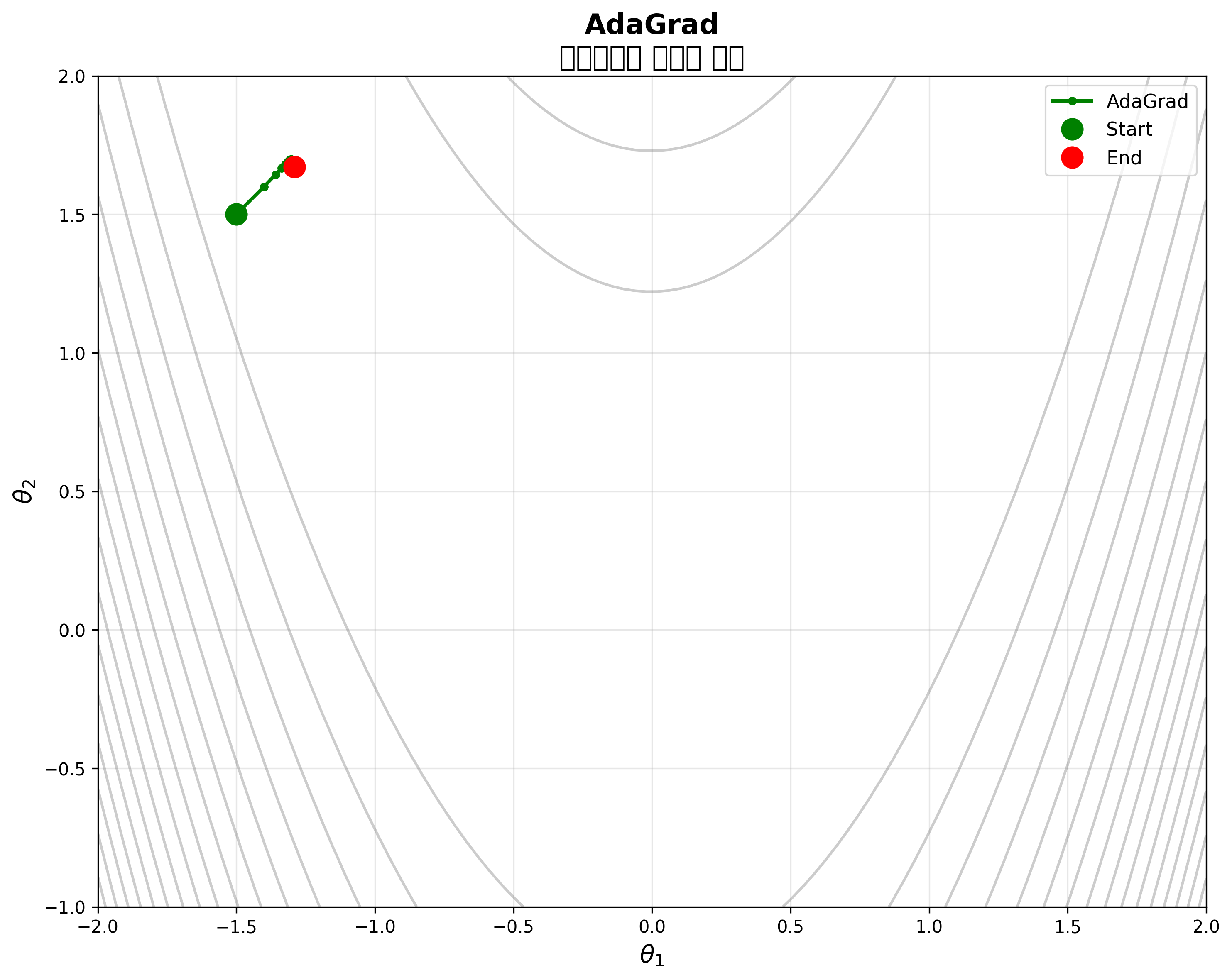
2nd Moment의 개념: 과거 그래디언트 제곱의 누적합을 사용하여 파라미터별 학습률을 조절한다.
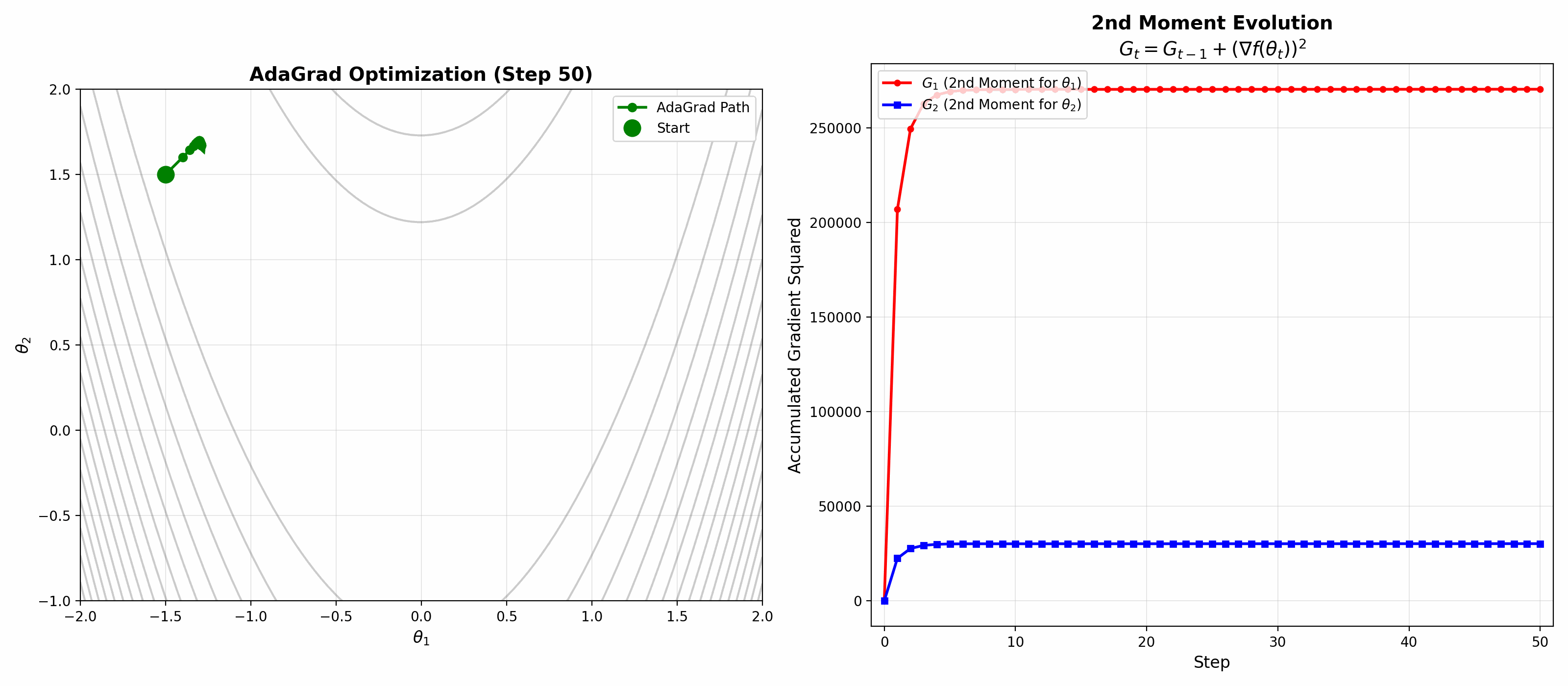
왼쪽: 최적화 경로가 실시간으로 업데이트되는 모습. 오른쪽: 2nd Moment (\(G_t = G_{t-1} + (\nabla f(\theta_t))^2\))가 누적되면서 학습률이 조절되는 과정을 시각화.
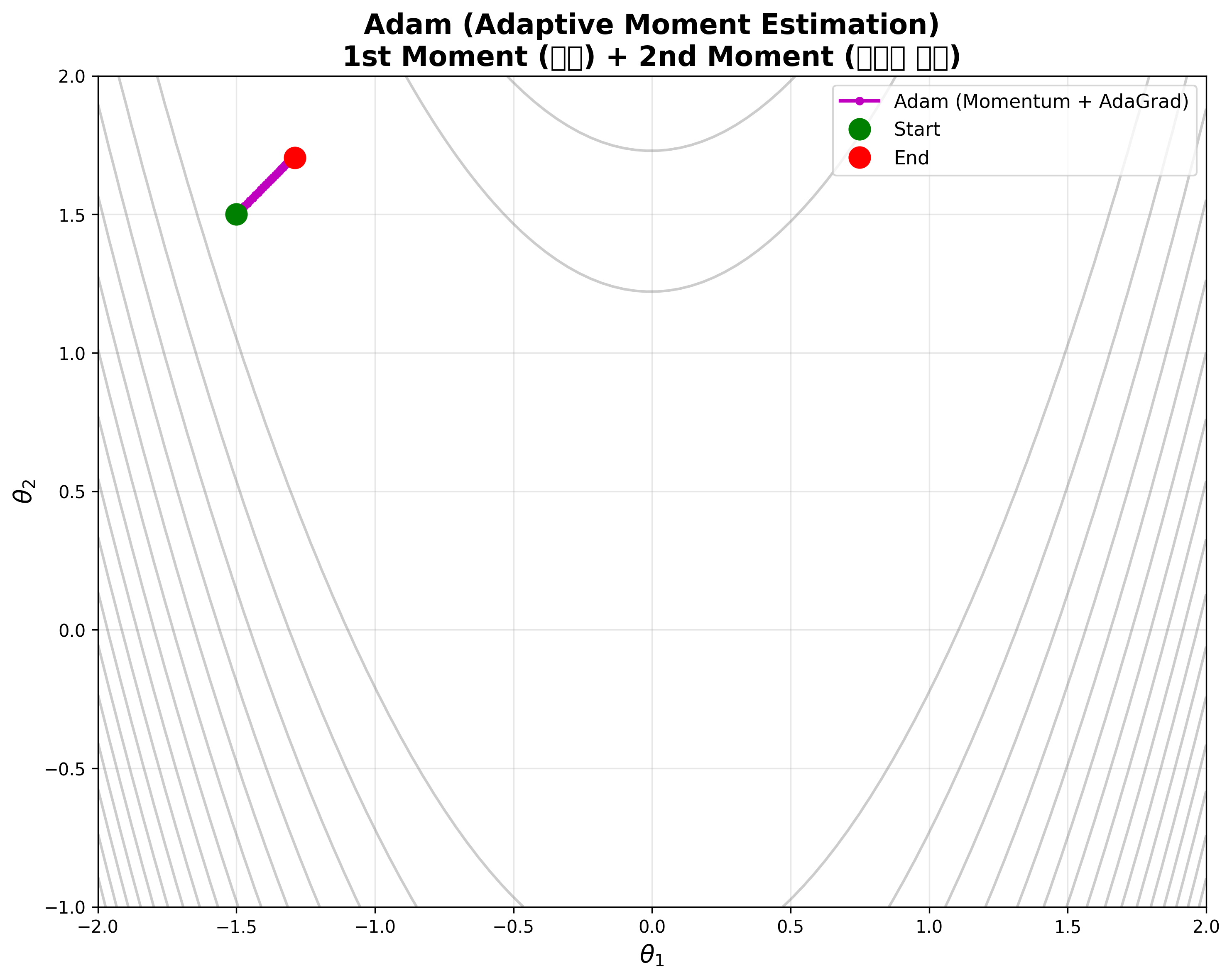
Adam (Adaptive Moment Estimation)
현재 가장 많이 쓰이는 기법, 1차 모멘트와 2차 모멘트를 모두 추정한다. Momentum의 가속도 효과와 AdaGrad의 파라미터별 보폭 조절 장점을 결합한 방식이다.
1st Moment (관성 효과): \(m_t = \beta_1 m_{t-1} + (1 - \beta_1) \nabla f(\theta_t)\)
2nd Moment (학습률 조절): \(v_t = \beta_2 v_{t-1} + (1 - \beta_2)(\nabla f(\theta_t))^2\)
Update: \(\theta_{t+1} = \theta_t - \frac{\tau}{\sqrt{v_t} + \epsilon} \hat{m}_t\)
여기서 \(\hat{m}_t\)와 \(\hat{v}_t\)는 bias correction된 모멘트이다.
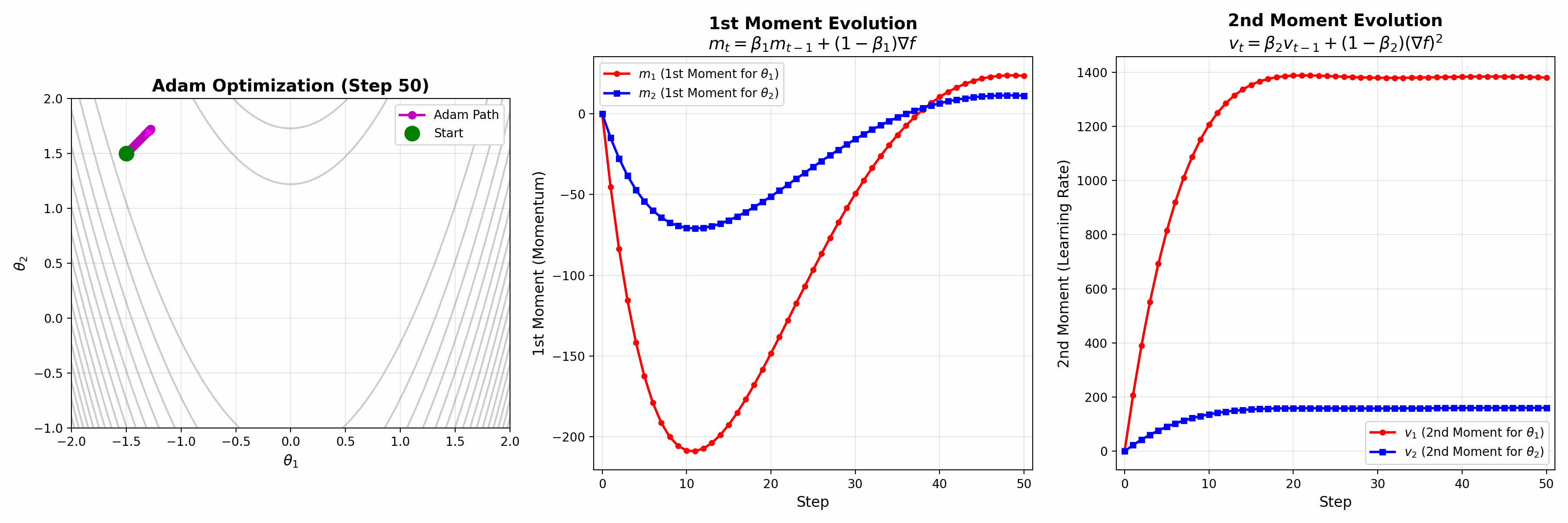
왼쪽: 최적화 경로가 실시간으로 업데이트되는 모습. 중간: 1st Moment (\(m_t\))가 관성 효과를 제공하며 진화하는 과정. 오른쪽: 2nd Moment (\(v_t\))가 학습률을 조절하며 변화하는 과정. 두 모멘트가 동시에 작동하여 빠르고 안정적인 수렴을 달성한다.
조금 더 정리해서 말하자면, Momentum의 가속도 효과와 AdaGrad의 파라미터별 보폭 조절 장점을 결합한 방식이 Adam이다.
Adaptive Learning Rates의 발전 과정
Momentum → AdaGrad → Adam으로 이어지는 발전 과정은 다음과 같은 통찰을 보여준다:
- Momentum: “과거 방향을 기억하면 가속이 붙는다” (1차 모멘트)
- AdaGrad: “자주 업데이트된 파라미터는 작은 보폭이 필요하다” (2차 모멘트)
- Adam: “두 가지를 모두 활용하면 더 빠르고 안정적이다”
Stochastic Gradient Descent (SGD)
지금까지 살펴본 방법들은 모두 전체 데이터셋의 gradient를 계산하는 것을 전제로 한다. 하지만 현실에서는 데이터셋이 수백만, 수십억 개의 샘플을 포함할 수 있다. 이 경우 한 번의 gradient 계산조차 엄청난 계산 비용을 요구한다.
SGD는 이러한 문제를 해결하기 위해 전체 데이터 대신 일부 샘플만 사용하여 gradient를 추정하는 확률적 접근 방법이다. 이는 계산 비용을 크게 줄이면서도, 기대값 관점에서 올바른 방향으로 학습할 수 있음을 보장한다.
Empirical Risk Minimization Approximation
\[\frac{1}{n} \sum_{i=1}^n L_i(\theta) = \mathbb{E}_{i \sim \{1,\ldots,n\}} [L_i(\theta)] \approx \frac{1}{|S|} \sum_{j \in S} L_j(\theta)\]이 수식은 전체 데이터에 대해 기대값을 작은 샘플 집합 \(S\)의 평균으로 대체함을 뜻한다.
Update Rule: \(\theta_{t+1} = \theta_t - \tau \cdot \frac{n}{|S|} \cdot \sum_{j \in S} \nabla L_j(\theta)\)
작은 샘플 집합 \(S\)를 Mini-batch라고 한다. 이것의 크기가 커질수록 그래디언트의 Variance가 줄어들어 안정적이다.
GD는 수렴 속도가 \(k \sim \log(\rho^{-1})\)로 빠르지만 한 스텝이 무겁다. 반면 SGD는 \(\mathbb{E}[\rho] \sim t^{-1}\)로 이론적으로 수렴은 느리지만 업데이트 측면에서 더 효율적이다.
GD vs SGD: Trade-off
이것은 전형적인 정확도 vs 효율성의 trade-off이다. GD는 정확하지만 느리고, SGD는 근사적이지만 빠르다. 실제로는 SGD가 큰 데이터셋에서 훨씬 실용적이며, mini-batch 크기를 조절하여 두 방법의 장점을 균형있게 활용할 수 있다.
Higher-order Techniques: Newton Method
지금까지 우리는 1차 미분 정보(gradient)만을 활용한 방법들을 살펴봤다. 하지만 함수의 2차 미분 정보(Hessian matrix)를 활용하면 더 정확하고 빠른 최적화가 가능하다. Newton Method는 이러한 2차 정보를 활용하는 대표적인 방법이다.
Taylor Expansion: 2차 근사
\[f(\theta_t + \delta) = f(\theta_t) + \delta^T \nabla f(\theta_t) + \frac{1}{2} \delta^T \nabla^2 f(\theta_t) \delta + O(\delta^3)\]이 수식은 현재 지점 \(\theta_t\)에서 함수를 2차 곡선으로 근사한 뒤, 그 근사식의 최솟값을 찾는 것을 의미한다. 이때의 Update Rule은:
Update Rule: \(\theta_{t+1} = \theta_t - [\nabla^2 f(\theta_t)]^{-1} \nabla f(\theta_t)\)
경사뿐만 아니라 지형의 곡률을 알기 때문에, 최적의 지점으로 단번에 혹은 매우 빠르게 수렴 가능하다. 하지만 파라미터 수가 \(d\)일 때, Hessian 계산/저장에 \(O(d^2)\), 역행렬 연산에 \(O(d^3)\)의 비용이 들어서 high dimensional 문제에는 적합하지 않다. 저차원 문제에만 사용된다.
Newton Method의 한계와 대안
Newton Method는 이론적으로 매우 강력하지만, 현대의 딥러닝 모델처럼 수백만 개의 파라미터를 가진 문제에는 적용하기 어렵다. 대신 Quasi-Newton methods (BFGS, L-BFGS 등)가 Hessian을 근사하여 비용을 줄이거나, Natural Gradient와 같은 변형된 방법들이 사용된다.
Distributed Learning: 분산 학습
SGD를 통해 계산 비용을 줄였고, Adaptive Learning Rates로 수렴 속도를 개선했지만, 여전히 단일 기기의 계산 능력과 메모리 한계에 부딪힐 수 있다. 현대의 대규모 모델(예: GPT, BERT)은 수십억 개의 파라미터를 가지며, 이를 학습하기 위해서는 여러 대의 기기를 동시에 활용하는 분산 학습(Distributed Learning)이 필수적이다.
Data Parallelism: 데이터 병렬화
동일한 모델의 복제본(Model Replicas)을 여러 기기에 할당하고, 각 기기는 서로 다른 데이터 배치를 처리한다. 각 기기에서 계산된 부분 그래디언트를 Parameter Server로 보내 모델 상태를 업데이트한다.
Model Parallelism: 모델의 병렬화
모델 자체가 너무 커서 한 기기의 메모리에 담기지 않을 때, 모델의 구조를 쪼개어 여러 기기에 분산시킨다. 예를 들어 CNN의 국소적 연결성 특성을 이용해 특정 레이어나 부분을 나누어 계산한다.
Parameter Server
여러 기기 사이의 통신 비용을 줄이면서 파라미터 업데이트를 자동화하고 관리하는 중앙 서버 역할을 한다. 각 워커가 계산한 gradient를 효율적으로 집계하고, 업데이트된 파라미터를 다시 분배하는 핵심 인프라이다.
결론
최적화는 Machine Learning의 핵심이다. 우리는 다음과 같은 발전 과정을 살펴봤다:
- Convexity 이해: 왜 최적화가 쉬운지/어려운지의 근본 원리
- Gradient Descent: 가장 기본적인 방법, gradient만으로 최적해 찾기
- Adaptive Learning Rates: 과거 정보를 활용한 개선 (Momentum, AdaGrad, Adam)
- SGD: 대규모 데이터를 위한 확률적 접근
- Newton Method: 2차 정보를 활용한 고차 방법
- Distributed Learning: 대규모 모델을 위한 분산 처리
각 방법은 이전 방법의 한계를 극복하기 위해 발전해왔으며, 실제로는 문제의 특성(데이터 크기, 모델 복잡도, 계산 자원)에 따라 적절한 방법을 선택하거나 조합하여 사용한다.