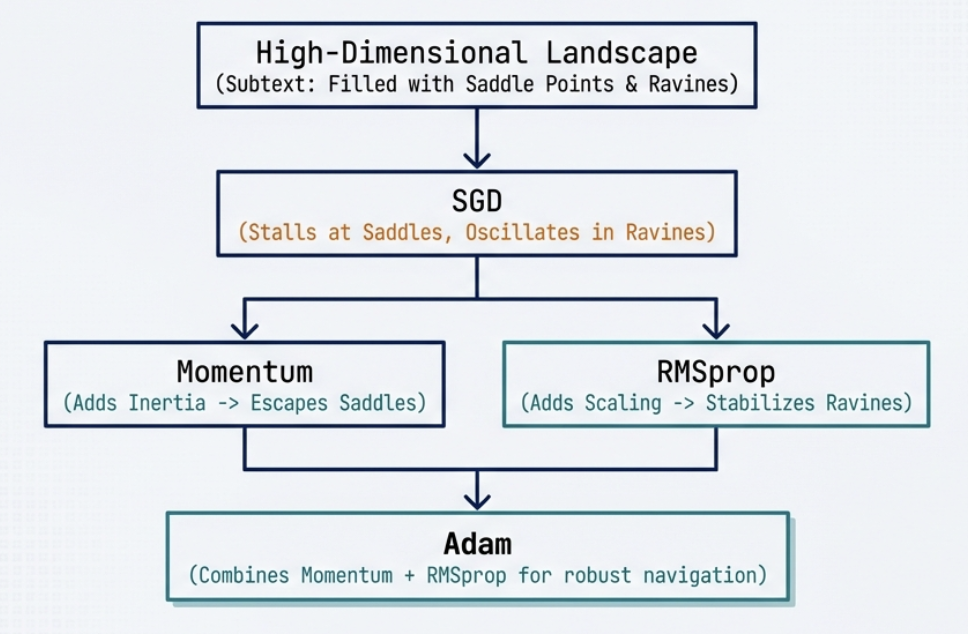
Saddle point of optimizer
Summary of Saddle point of optimizer
Saddle Point
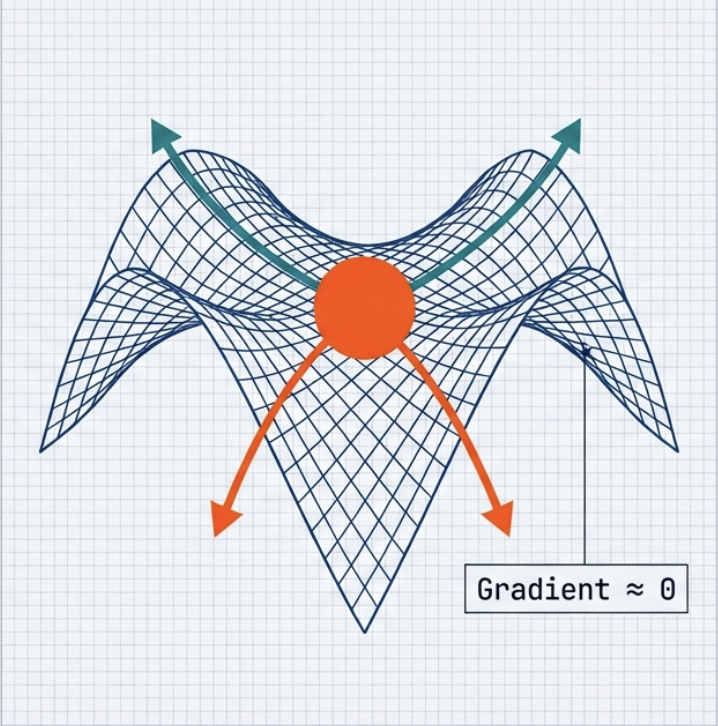
Definition
Saddle point 는 어떤 방향에서는 minimum 처럼 보이고, 다른 방향에서는 maximum 처럼 보이는 지점.
즉,
- gradient 는 거의 0 이지만, 최솟값은 아닌 경우이다.
딥러닝의 고차원 loss landscape 에서는 local minimum 보다 saddle point 가 훨씬 더 흔하다.
걍 한방향으로는 내려가고 다른방향으로는 올라가는것.
Problem
- gradient \(\equiv 0\) : SGD 가 멈춘것처럼 보임 그럼 minima 로 혼동되기 쉬움
- curvature 가 방향마다 다르다 : 최적화 어려움
Ravine
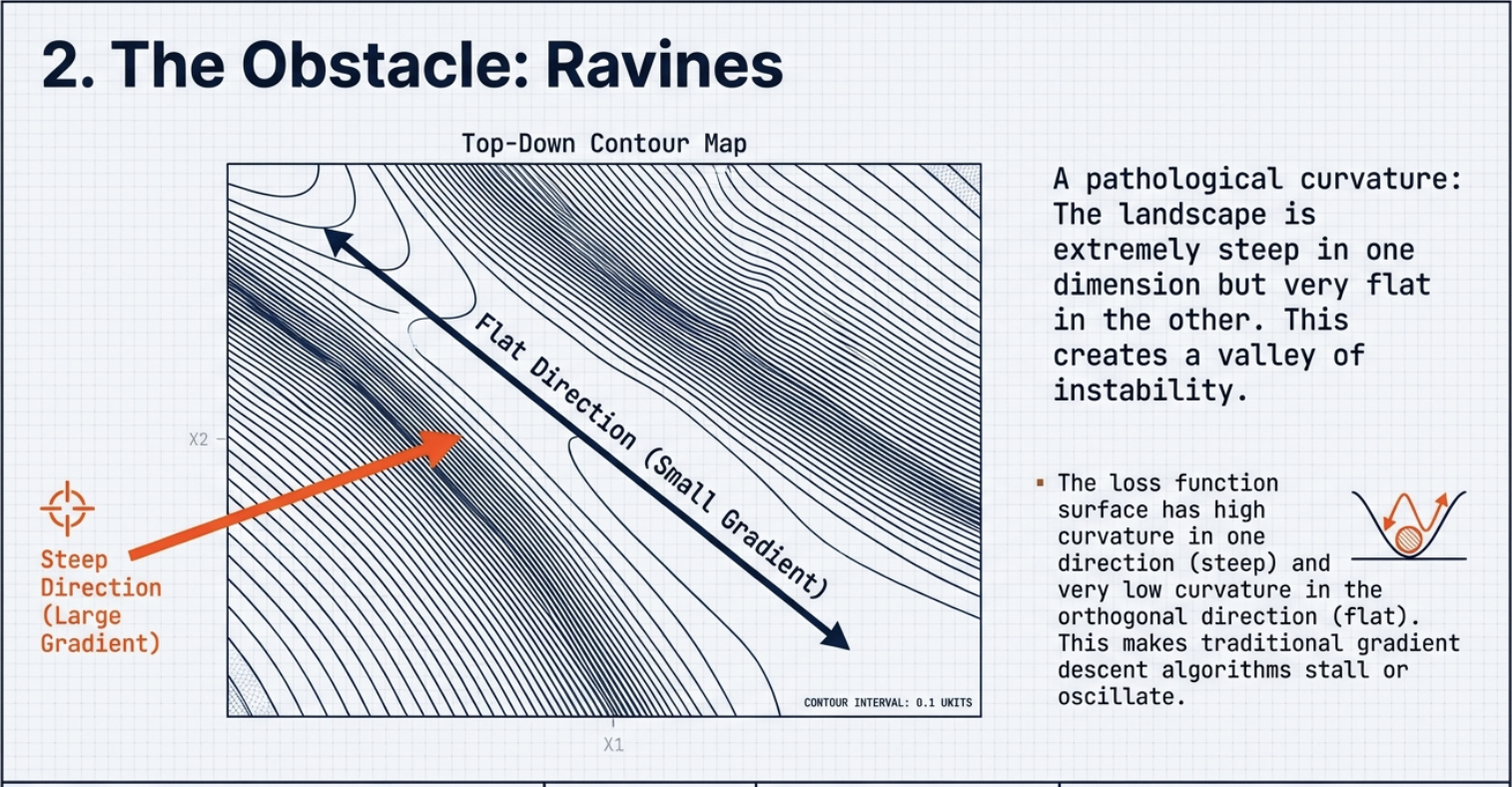
Definition of Ravine
- 한 방향은 steep = big gradient
- 다른 방향을 flat = small graident
를 둘다 가진 긴 골짜기 형태
Problem of Ravine
SGD 는 steep 한 방향으로 계속 튕기면서 zigzag 하니까 수렴이 느리고 불안정함.
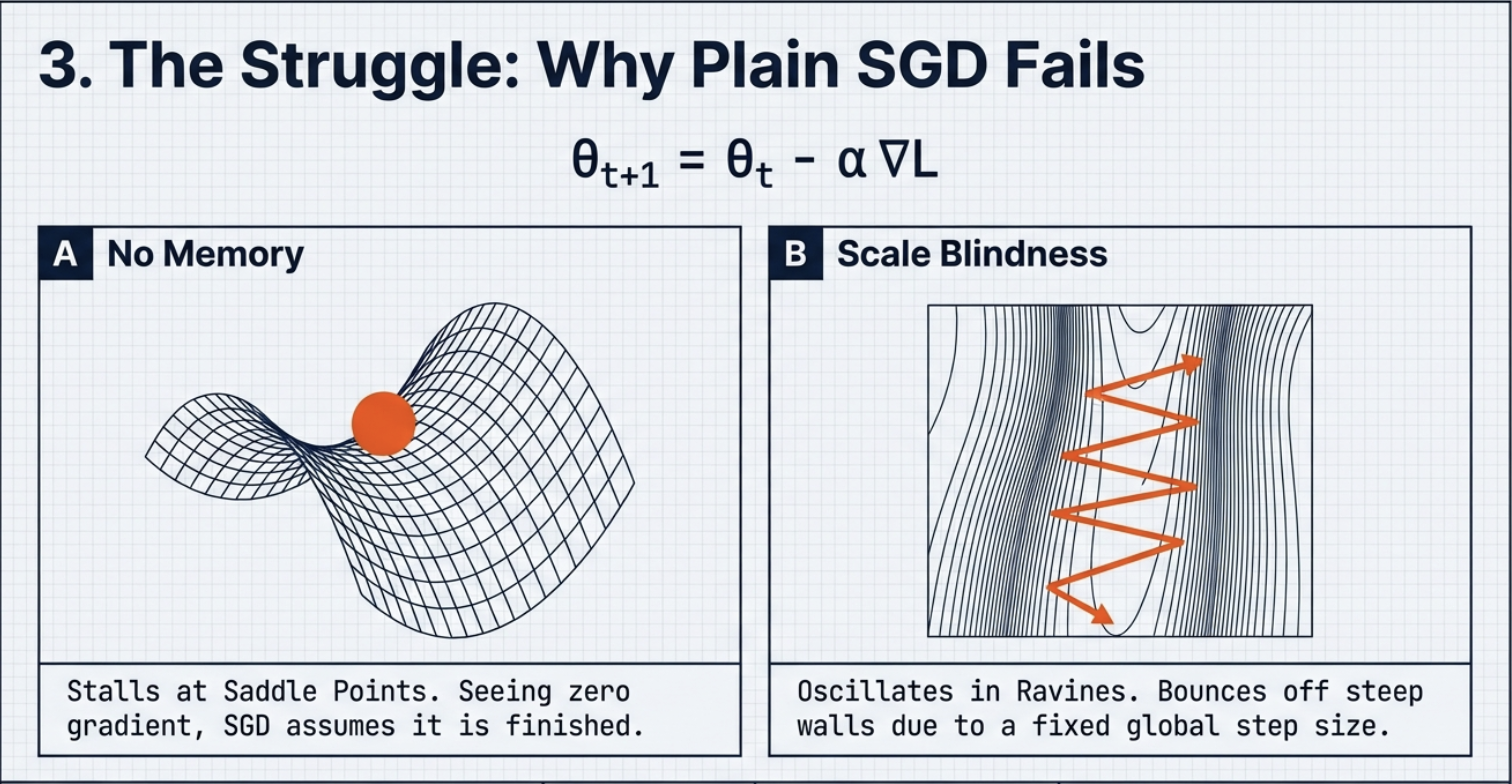
Fail of plain SGD
SGD 는 그레디언트의 현재 값만 사용한다. 그럼 방향의 정보가 기억되지 않고 그 스케일 차이가 고려되지 않는다. 그럼 saddle point 근처에서 정체되고, ravine 에서는 oscillate 함. 이것에 대한 해결책으로 Momentum 들이 나옴. 왜냐면 모멘텀 자체가 magnitude(direction) 와 size(step size)이니까…
Escape Saddle point
Ideation
\[m_t = \beta m_{t-1} - \alpha g_t\]그래디언트를 누적시키자! 관성을 만들어버리자! 그럼 flat 한 방향에서도 이전 속도로 이동이 가능하겠지?
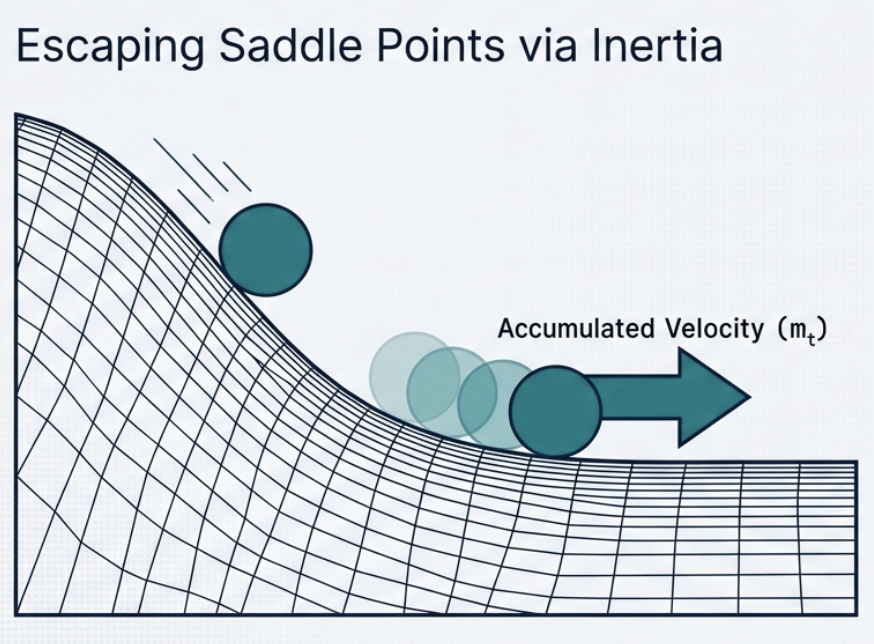
그럼 갑자기 gradient 가 0 에 가까운 부분에서도 관성적으로 빠르게 통과시킬 수 있고, 이렇게 되면 oscillation 이 어느정도 완화된다.
- Accumulates past gradients to build velocity
- Allows the optimizer to overshoot saddle points even when the current gradient is zero.
RMSprop
Stabilize of Ravine 하는 거. = oscillation 을 안정화시키자 = ravine 에서 지그재그로 튕기는 걸 없애보자 = Rescale, step size 정규화
\[v_t = \beta v_{t-1} + (1- \beta) g_t^2\]RMSprop keeps a moving average of squared gradients. (Variance, Size 정보) It normalizes step size individually for each parameter, taming the zig-zag oscillation
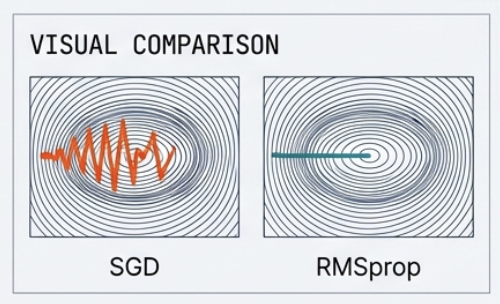
즉 steep 한 방향에서 stp 을 줄이고, flat 한 방향에서는 step 을 유지하면서 zigzag를 제거함.
Adam
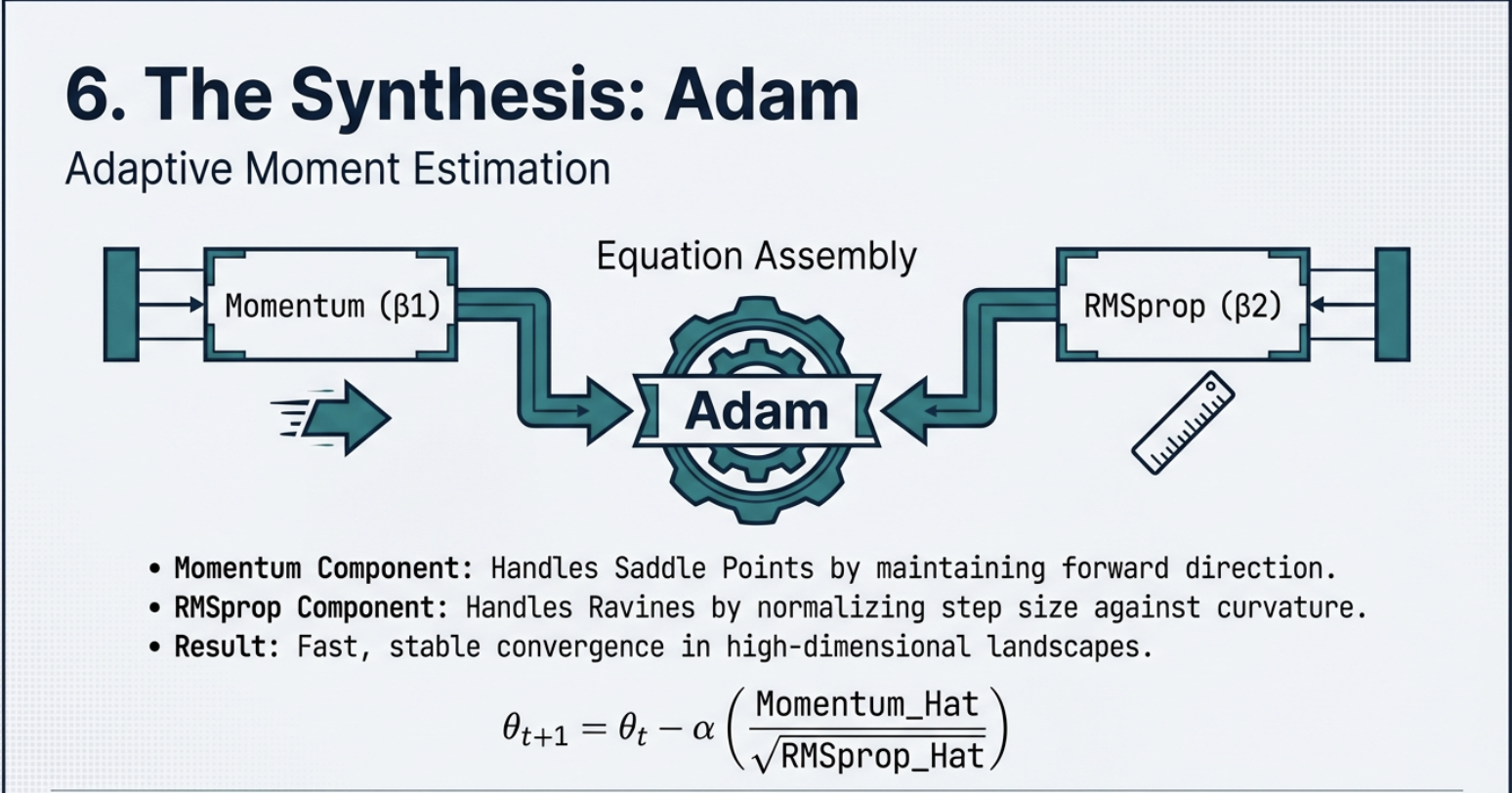
둘다 해결. 그래서 파라미터가 2개가 추가되고,
- Momentum (\(\beta_1\)) : 방향 안정화
- RMSprop (\(\beta_2\)) : 스케일 정규화
이렇게 하면 escape saddle point, stabilize ravine, 그리고 noisy, sparse gradient 에도 강함.
Photo memory